体验正则表达式的魅力:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // 获取字符串中所有的数值 let str = 'cyy2020cyy2xxx'; //不使用正则的情况 let nums = [...str].filter(item => !Number.isNaN(parseInt(item))).join(''); console.log(nums); // 使用正则的情况 let num2 = str.match(/\d/g).join(''); console.log(num2); </script></body></html>
字面量创建正则表达式:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = 'cyy2020cyy2xxx'; console.log(/cyy/.test(str)); //不能直接使用变量 let word = 'cyy'; console.log(/word/.test(str)); //使用这种方式,使用变量 console.log(eval(`/${word}/`).test(str)); </script></body></html>
使用对象创建正则表达式:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <div>这里是cyy用来检测正则的测试文本~~~</div> <script> // let str = 'cyy2020cyy2xxx'; // //第二个参数是模式 // let reg = new RegExp('cyy', 'g'); // console.log(reg.test(str)); // //使用变量 // let word = 'cyy'; // let reg2 = new RegExp(word, 'g'); // console.log(reg2.test(str)); //demo let text = prompt('请输入要检测的文本,支持正则'); let reg = new RegExp(text, 'g'); let div = document.querySelector('div'); div.innerHTML = div.innerHTML.replace(reg, search => { return `<span >${search}</span>`; }); </script></body></html>
选择符的使用:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = 'cyy000'; // |代表选择符,符号左边的表达式或者右边的表达式是否满足 // 左边匹配的是cyy,而不是一个y console.log(/cyy|x/.test(str)); let tel = '010-8888888'; console.log(/^(010|020)\-\d{7,8}$/.test(tel)); </script></body></html>
原子表与原子组中的选择符:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // 原子表 let str = '1122334455'; let reg = /[1234567]/; console.log(str.match(reg)); //原子组 let str2 = '1122334455'; let reg2 = /(11|44)/g; console.log(str2.match(reg2)); </script></body></html>

转义需要好好理解:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // .代表除换行符外的所有字符 // let price = 33.47; // console.log(/\d+\.\d+/.test(price)); //对象创建的正则需要双重转义 // let price = 33.47; // let reg = new RegExp('\d+\.\d+'); // console.log(reg); // console.log(reg.test(price)); let price = 33.47; let reg = new RegExp('\\d+\\.\\d+'); console.log(reg); console.log(reg.test(price)); </script></body></html>
字符边界约束:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <input type="text" name='user'> <span style='color:red;'></span> <script> document.querySelector('[name=user]').addEventListener('keyup', function () { console.log(this.value); let flag = this.value.match(/^[a-z]{3,5}$/); document.querySelector('span').innerHTML = flag ? '成功' : '失败'; }); </script></body></html>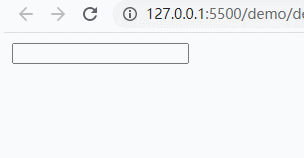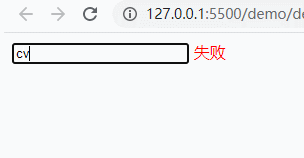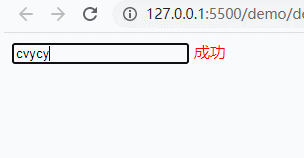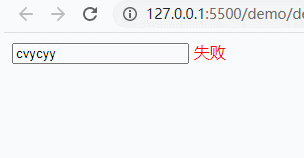
数值与空白元字符:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // let str = '20201111'; // console.log(str.match(/\d/)); // // 模式符g 全局匹配 // console.log(str.match(/\d/g)); //获取电话号码 // let tel = "'姓名: 'cyy', 电话: 010-1111111; 姓名: 'cyy2', 电话: 030-99999999"; // console.log(tel.match(/\d{3}-\d{7,8}/g)); //获取中文 [^]表示方括号里面的都不要 let tel = "'姓名: 'cyy', 电话: 010-1111111; 姓名: 'cyy2', 电话: 030-99999999"; console.log(tel.match(/[^':,-\da-z\s;]+/g)); //\d 数字 \D 非数字 // let tel = "'姓名: 'cyy', 电话: 010-1111111; 姓名: 'cyy2', 电话: 030-99999999"; // console.log(tel.match(/\D+/g)); // \s匹配空白,包括空格和换行符 // let str = ' 11\n'; // console.log(str.match(/\s/g)); // \S匹配非空白,包括空格和换行符 let str = ' 11\n'; console.log(str.match(/\S+/g)); </script></body></html>
w与W元字符:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // \w 字母数字下划线 // let str = 'cyy123_-@@'; // console.log(str.match(/\w+/)); // let email = '965794175@qq.com'; // console.log(email.match(/^\w+@\w+\.\w+$/)); // 5-10为字母数字下划线,并且是字母开头 let user = prompt('请输入用户名'); console.log(user.match(/^[a-z]\w{4,9}$/)); </script></body></html>
点元字符的使用:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // . 除空白符之外的所有字符 // let str = 'cswj+4!j@;;'; // console.log(str.match(/.+/)); //这里的+是贪婪模式 // .需要转义 // let str = 'https://www.baidu.com'; // console.log(str.match(/^https?:\/\/\w+\.\w+\.\w+$/)); // .需要转义 // let str = ` // www.baidu.com // www.taobao.com // `; // console.log(str.match(/.+/)); // // s模式符:忽略换行符 // console.log(str.match(/.+/s)); let tel = '010 - 12345678'; console.log(tel.match(/\d{3} - \d{8}/)); console.log(tel.match(/\d{3}\s-\s\d{8}/)); </script></body></html>
如何精巧的匹配所有字符:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = ` <span> cyy @@@ hahahah </span> `; console.log(str.match(/[\w\W]+/)); console.log(str.match(/[\d\D]+/)); </script></body></html>
i与g模式修饰符:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = 'cyyCyy'; console.log(str.match(/c/i)); console.log(str.match(/c/g)); console.log(str.match(/c/gi)); console.log(str.replace(/c/gi, '@')); </script></body></html>
m多行匹配修正符实例:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = ` #1 js,200元 # #2 html,104元 # #3 css # cyy `; let lessons = str.match(/^\s*#\d+\s+.+\s+#$/gm).map(item => { item = item.replace(/^\s*#\d+\s*/, '').replace(/\s+#/, ''); [name, price] = item.split(','); return { name, price }; }); console.log(lessons); </script></body></html>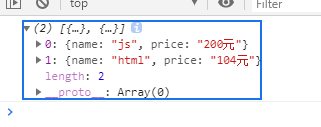
汉字与字符属性:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // u修饰符:正确处理四个字符的 UTF-16 编码 //每个字符都有属性,如L属性表示是字母,P 表示标点符号,需要结合 u 模式才有效。 //其他属性简写可以访问 https://www.unicode.org/Public/UCD/latest/ucd/PropertyValueAliases.txt 网站查看。 // let str = 'cyy2020.永远最棒棒~'; // console.log(str.match(/\p{L}/gu));//字母 // console.log(str.match(/\p{N}/gu));//数字 // console.log(str.match(/\p{P}/gu));//标点符号 //找中文 //字符也有unicode文字系统属性 Script=文字系统,下面是使用 \p{sc=Han} 获取中文字符 han为中文系统 //其他语言请查看 // console.log(str.match(/\p{sc=Han}/gu)); let str = '𝒳𝒴'; console.log(str.match(/[𝒳𝒴]/));//单独匹配时乱码 console.log(str.match(/[𝒳𝒴]/u));//正确识别宽字节 </script></body></html>
lastIndex属性的作用:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = 'cyy is a girl'; // console.log(str.match(/\w/)); // console.log(str.match(/\w/g)); //没有组信息 //非全局模式下lastIndex不会向后走 // let reg = /\w/; // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); //全局模式下lastIndex会向后走 let reg = /\w/g; // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); while (res = reg.exec(str)) { console.log(res); } </script></body></html>
有效率的y模式:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // y粘连模式,必须连续 // let str = 'yycyyccc'; // let reg = /yy/g; // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); // let reg = /yy/y; // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); let str = 'cyy的qq群是:1111111,2222222,3333333,cyy的年龄是:18'; let reg = /(\d+),?/y; reg.lastIndex = 9; // console.log(reg.exec(str)); // console.log(reg.exec(str)); // console.log(reg.exec(str)); let qq = []; while (res = reg.exec(str)) { qq.push(res[1]); } console.log(qq); </script></body></html>
原子表基本上使用:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // let str = '123456'; // console.log(str.match(/[246]/g)); // let str = '2020-11-28'; // let str2 = '2020/11/28'; // console.log(str.match(/^\d{4}[-\/]\d{2}[-\/]\d{2}$/g)); // console.log(str2.match(/^\d{4}[-\/]\d{2}[-\/]\d{2}$/g)); //分隔符必须一致 let str = '2020-11/28'; let str2 = '2020/11/28'; console.log(str.match(/^\d{4}([-\/])\d{2}\1\d{2}$/g)); console.log(str2.match(/^\d{4}([-\/])\d{2}\1\d{2}$/g)); </script></body></html>
区间匹配:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <input type="text" name='user'> <script> // let str = '1234'; // console.log(str.match(/[0-9]+/g)); // let str = 'abcd1234'; // console.log(str.match(/[a-z]+/g)); let input = document.querySelector('[name=user]'); input.addEventListener('keyup', function () { console.log(this.value.match(/[a-z]\w{3,5}/)); }) </script></body></html>
排除匹配:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // let str = '1234'; // console.log(str.match(/[12]/g)); // console.log(str.match(/[^12]/g)); let str = 'cyy是小仙女呀'; console.log(str.match(/[^\w]+/g)); console.log(str.match(/\p{sc=Han}+/gu)); </script></body></html>
原子表字符不解析:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = '(cyy.)'; // ()在这里代表原子组 // console.log(str.match(/()/g)); // ()在这里代表普通括号 // console.log(str.match(/[()]/g)); // .在这里表示除空白符外的所有字符 console.log(str.match(/.+/g)); // .在这里表示.符号本身 console.log(str.match(/[.+]/g)); </script></body></html>
使用原子表匹配所有内容:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = ` cyy1 cyy2 `; console.log(str.match(/.+/));//无法匹配换行符 console.log(str.match(/.+/s));//可以匹配换行符 console.log(str.match(/[\s\S]+/)); console.log(str.match(/[\d\D]+/)); console.log(str.match(/[\w\W]+/)); </script></body></html>
正则操作DOM:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <p>p</p> <h1>h1</h1> <h3>h3</h3> <script> let reg = /<(h[1-6])>[\s\S]*<\/\1>/gi; document.body.innerHTML = document.body.innerHTML.replace(reg, ''); </script></body></html>
认识原子组:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = `<h1>h1</h1> <h2>h2</h2>`; let reg = /<(h[1-6])>[\s\S]*<\/\1>/gi; console.log(str.match(reg)); </script></body></html>
邮箱验证中原子组的使用:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <input type="email" name="email" value="965794175@qq.com.cn"> <script> let reg = /[\w-]+@([\w-]+\.)+(com|cn|cc|net|org)/gi; let email = document.querySelector('[name=email]').value; console.log(email.match(reg)); </script></body></html>
原子组引用完成替换操作:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = ` <h1>h1</h1> <div>div</div> <h3>h3</h3>`; //把h1-h6替换成p let reg = /<(h[1-6])>([\s\S]+)<\/\1>/gi; console.log(str.match(reg)); console.log(str.replace(reg, `<p>$2</p>`)); let res = str.replace(reg, (p0, p1, p2) => { // console.log(p0, p1, p2); return `<p>${p2}</p>`; }); console.log(res); </script></body></html>
嵌套分组与不记录组:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = ` https://www.baidu.com http://www.baidu.com https://baidu.com `; //获取域名 // ? 表示可有可无 // 圆括号里 ?: 表示不记录组 let reg = /https?:\/\/((?:\w+\.)?\w+\.(?:com|cn|net|org|cc))/gi; // console.log(reg.exec(str)); let urls = []; while (res = reg.exec(str)) { // console.log(res); urls.push(res[1]);//0是原数组,1是第一个分组 } console.log(urls); </script></body></html>
多种重复匹配基本使用:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // let str = 'cyy'; // + 1个或者多个,贪婪匹配 // console.log(str.match(/cy+/)); // let str = 'c'; // * 0个或者多个,贪婪匹配 // console.log(str.match(/cy*/)); // let str = 'cy'; // // ? 0个或者1个,贪婪匹配 // console.log(str.match(/cy?/)); let str = 'cyy'; // {} 表示范围,贪婪匹配 console.log(str.match(/cy{2,5}/)); </script></body></html>
重复匹配对原子组的影响与电话号正则:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // let str = 'cyyyyycycycy'; // console.log(str.match(/(cy)+/g)); let tel = '010-1234567'; console.log(tel.match(/^0\d{2,3}-\d{7,8}$/g)); </script></body></html>
网站用户名验证 :
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <input type="text" name='username'> <script> document.querySelector('[name=username]').addEventListener('keyup', (e) => { let value = e.target.value; //用户名3-8位,字母数字下划线,字母开头 console.log(value.match(/^[a-z][\w-]{2,7}$/i)); }) </script></body></html>
批量使用正则完成密码验证:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <input type="text" name='pwd'> <script> document.querySelector('[name=pwd]').addEventListener('keyup', (e) => { let value = e.target.value; //密码是数字或者字母5-10位,并且必须包含大写字母和数字 let regs = [ /^[a-z0-9]{5,10}$/i, /[A-Z]/, /\d/ ]; let res = regs.every(reg => reg.test(value)); console.log(res); }); </script></body></html>
禁止贪婪:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = 'cyyyyyy'; // console.log(str.match(/cy+/));//默认贪婪 // console.log(str.match(/cy+?/));//禁止贪婪 // console.log(str.match(/cy*/));//默认贪婪 // console.log(str.match(/cy*?/));//禁止贪婪 // console.log(str.match(/cy{2,6}/));//默认贪婪 // console.log(str.match(/cy{2,6}?/));//禁止贪婪 // console.log(str.match(/cy{2,}/));//默认贪婪 // console.log(str.match(/cy{2,}?/));//禁止贪婪 console.log(str.match(/cy?/));//默认贪婪 console.log(str.match(/cy??/));//禁止贪婪 </script></body></html>
标签替换的禁止贪婪使用:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <main> <span>cyy1</span> <span>cyy2</span> <span>cyy3</span> </main> <script> //把span换成h4,标红,前缀加上小可爱- const main = document.querySelector('main'); // ?禁止贪婪 let reg = /<span>([\s\S]+?)<\/span>/ig; main.innerHTML = main.innerHTML.replace(reg, (res, h1) => { return `<h4 style="color:red;">小可爱-${h1}</h4>`; }); </script></body></html>
使用matchAll完成全局匹配:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <h1>cyy1</h1> <h2>cyy2</h2> <h3>cyy3</h3> <script> let reg = /<(h[1-6])>([\s\S]+?)<\/\1>/ig; console.log(document.body.innerHTML.match(reg)); console.log(document.body.innerHTML.matchAll(reg)); let res = document.body.innerHTML.matchAll(reg); let arr = []; for (const iterator of res) { console.dir(iterator); arr.push(iterator[2]); } console.table(arr); </script></body></html>

为低端浏览器定义原型方法matchAll
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <h1>cyy1</h1> <h2>cyy2</h2> <h3>cyy3</h3> <script> String.prototype.matchAll = function (reg) { let res = this.match(reg); // console.log(res); if (res) { let str = this.replace(res[0], '^'.repeat(res[0].length)); let match = str.matchAll(reg) || []; return [res, ...match]; } } let body = document.body.innerHTML; let res = body.matchAll(/<(h[1-6])>([\s\S]+?)<\/\1>/ig); console.log(res); </script></body></html>
使用exec完成全局匹配:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <h1>cyy1</h1> <h2>cyy2</h2> <h3>cyy3</h3> <script> // let str = 'cyyccyy'; // let reg = /y/gi;//必须加上g修饰符,lastIndex才会发生改变 // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); // console.log(reg.exec(str)); // console.log(reg.lastIndex); // let arr = []; // while (res = reg.exec(str)) { // arr.push(res); // } // console.log(arr); let arr = []; function search(str, reg) { while (res = reg.exec(str)) { arr.push(res); } return arr; } search(document.body.innerHTML, /<(h[1-6])>[\s\S]+?<\/\1>/gi); console.log(arr); </script></body></html>
字符串正则方法search与match
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // search 字符串的搜索 // let str = 'yyccyy'; // console.log(str.search('c')); // console.log(str.search(/c/g)); // match 字符串的匹配 // let str = 'yyccyy'; // console.log(str.match('c')); // console.log(str.match(/c/g)); let str = ` https://www.baidu.com http://www.taobao.com.cn https://google.cn `; let reg = /https?:\/\/(\w+\.)?(\w+\.)+(com|cn|net|org|cc)/gi; console.log(str.match(reg)); </script></body></html>
字符串正则方法matchAll与split
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // search 字符串的搜索 // let str = 'yyccyy'; // console.log(str.search('c')); // console.log(str.search(/c/g)); // match 字符串的匹配 // let str = 'yyccyy'; // console.log(str.match('c')); // console.log(str.match(/c/g)); // let str = ` // https://www.baidu.com // // https://google.cn // `; // let reg = /https?:\/\/(\w+\.)?(\w+\.)+(com|cn|net|org|cc)/gi; // console.log(str.match(reg)); // let reg = /https?:\/\/(?:\w+\.)?(?:\w+\.)+(?:com|cn|net|org|cc)/gi; // let res = str.matchAll(reg); // for (const iterator of res) { // console.log(iterator); // } let str = '2020-11-30'; let str2 = '2020/11/30'; console.log(str.split(/[-\/]/)); console.log(str2.split(/[-\/]/)); </script></body></html>
$符在正则替换中的使用:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // let str = '2020/11/30'; // console.log(str.replace(/[\/]/, '-')); // console.log(str.replace(/[\/]/g, '-')); // let str = '(010)99999999 (020)8888888'; // let reg = /\((\d{3,4})\)(\d{7,8})/g; // console.log(str.match(reg)); // console.log(str.replace(reg, "$1-$2")); let str = '=cyy='; // $& 匹配到的内容 $` 匹配内容的左边 $' 匹配内容的右边 console.log(str.replace(/cyy/, "$`可爱$&可爱$'")); </script></body></html>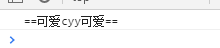
$&使用
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <main>cyy喜欢吃炒年糕,cyy也喜欢吃汤年糕</main> <script> const main = document.querySelector('main'); main.innerHTML = main.innerHTML.replace(/年糕/g, "<a href='http://www.baidu.com'>$&</a>") </script></body></html>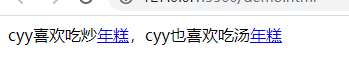
原子组在替换中的使用技巧:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <main> <a href="http://www.baidu.com" style='color:pink'>baidu</a> <a id='link' href="http://baidu.com">baidu</a> <a href="http://google.com">baidu</a> <h4>http://www.baidu.com</h4> </main> <script> const main = document.querySelector('main'); let reg = /(<a.*href=['"])(http)(:\/\/)(www\.)?(baidu)/gi; main.innerHTML = main.innerHTML.replace(reg, (v, ...args) => { console.log(args); args[1] += 's'; args[3] = args[3] || 'www.'; return args.splice(0, 5).join(''); }); </script></body></html>
原子组别名:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let str = ` <h1>h1</h1> <span>span</span> <h4>h4</h4> `; // let reg = /<(h[1-6])>(.*?)<\/\1>/gi; // console.log(str.replace(reg, "<div>$2</div>")); //起别名 let reg = /<(h[1-6])>(?<con>.*?)<\/\1>/gi; console.log(str.replace(reg, "<div>$<con></div>")); </script></body></html>
使用原子组别名优化正则:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <main> <a href="https://www.baidu.com">baidu</a> <a href="https://www.taobao.com">taobao</a> <a href="https://www.google.com">google</a> </main> <script> // [{link:,title:}] const main = document.querySelector('main'); // let reg = /<a.*?href=(['"])(?<link>.*?)\1>(?<title>.*?)<\/a>/i; // console.log(main.innerHTML.match(reg)); let reg = /<a.*?href=(['"])(?<link>.*?)\1>(?<title>.*?)<\/a>/gi; let arr = []; for (const iterator of main.innerHTML.matchAll(reg)) { console.log(iterator['groups']); arr.push(iterator['groups']); } console.table(arr); </script></body></html>
正则方法test
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <input type="text" name='email'> <script> const mail = document.querySelector('[name=email]'); mail.addEventListener('keyup', (e) => { let value = e.target.value; let res = /^[\w-]+@[\w+\.]+(com|cn|org|cc)$/i.test(value); console.log(res); }) </script></body></html>
正则方法exec
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <main> cyy非常可爱,cyy到底有多可爱?baidu.com </main> <script> const mail = document.querySelector('main').innerHTML; let reg = /cyy/gi; // console.log(mail.match(reg)); // console.log(reg.exec(mail)); // console.log(reg.lastIndex); // console.log(reg.exec(mail)); // console.log(reg.lastIndex); // console.log(reg.exec(mail)); // console.log(reg.lastIndex); let count = 0; while (res = reg.exec(mail)) { count++; } console.log(count); </script></body></html>
?= 断言匹配:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <main> cyy非常可爱,cyy可爱就可爱在…… </main> <script> const main = document.querySelector('main'); let reg = /cyy(?=可爱)/gi; main.innerHTML = main.innerHTML.replace(reg, '<a href="https://www.baidu.com">$&</a>'); </script></body></html>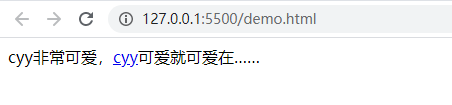
使用断言规范价格:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // 给所有金钱补上 .00 格式 let lessons = ` js,200元,300次 html,300.00元,105次 css,140元,260次 `; let reg = /(\d+)(\.00)?(?=元)/gi; let res = lessons.replace(reg, (v, ...args) => { console.log(args); args[1] = args[1] || '.00'; return args.splice(0, 2).join(''); }); console.table(res); </script></body></html>
?<= 断言匹配
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <main> <a href="https://www.baidu.com">baidu</a> <a href="https://www.google.com">google</a> </main> <script> // let str = 'cyy123ccc098'; // let reg = /(?<=cyy)\d+/gi; // console.log(str.match(reg)); const main = document.querySelector('main'); const reg = /(?<=href=(["'])).+(?=\1)/gi; // console.log(main.innerHTML.match(reg)); main.innerHTML = main.innerHTML.replace(reg, 'http://www.taobao.com'); </script></body></html>
使用断言模糊电话号:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> let users = ` cyy1电话:12345678911 cyy2电话:99999678911 `; let reg = /(?<=\d{7})\d{4}/gi; users = users.replace(reg, '*'.repeat(4)); console.log(users); </script></body></html>
?!断言匹配:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // ?= 后面是什么 // ?! 后面不是什么 let str = 'cyy2020ccc'; let reg = /[a-z]+(?!\d)/gi; // 错误 let reg = /[a-z]+(?!\d)$/gi; // 正确 console.log(str.match(reg)); </script></body></html>
断言限制用户名关键词:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <input type="text" name='user'> <script> //要求注册名中不能包含cyy let input = document.querySelector('[name=user]'); input.addEventListener('keyup', function () { // let reg = /^(?!.*cyy.*).*/gi; let reg = /^(?!.*cyy.*)[a-z]{5,6}$/gi; console.log(this.value.match(reg)); }) </script></body></html>
?<!断言匹配:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <script> // ?<! 限制前面不是什么 let str = 'cyy999ccc'; let reg = /^(?<!\d+)[a-z]+/gi; console.log(str.match(reg)); </script></body></html>
使用断言排除法统一数据:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <meta http-equiv="X-UA-Compatible" content="ie=edge" /> <title>Document</title></head><body> <main> <a href="https://www.baidu.com/1.jpg">1.jpg</a> <a href="https://oss.baidu.com/2.jpg">2.jpg</a> <a href="https://cdn.baidu.com/3.jpg">3.jpg</a> <a href="https://baidu.com/4.jpg">4.jpg</a> </main> <script> // ?<! 限制前面不是什么 const main = document.querySelector('main'); //过滤oss let reg = /https:\/\/([a-z]+)?(?<!oss)\..+?(?=\/)/gi; main.innerHTML = main.innerHTML.replace(reg, (v) => { return 'https://oss.baidu.com'; }); </script></body></html>
原文转载:http://www.shaoqun.com/a/494416.html
环球华网:https://www.ikjzd.com/w/1063
wish:https://www.ikjzd.com/w/105
square:https://www.ikjzd.com/w/2106
体验正则表达式的魅力:<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"/><metaname="viewport"content="width=device-width,initial-scale=1.0"
立刻网:立刻网
tineye:tineye
【泰国旅游安全吗】--泰国旅游安全情况:【泰国旅游安全吗】--泰国旅游安全情况
2018年末,亚马逊,ebay,wish,速卖通你应该选择谁(2):2018年末,亚马逊,ebay,wish,速卖通你应该选择谁(2)
日本北海道的最佳旅游时间是什么时候?:日本北海道的最佳旅游时间是什么时候?
No comments:
Post a Comment