- 前言
- 类签名
- 泛型
- Serializable和Cloneable
- Deque
- List和AbstractList
- RandomAccess接口(没实现)
- 变量
- 构造函数
- 常用方法
- List体系下的方法:
- add(E e)
- linkLast(E e)方法
- 双向链表的基本形式
- 对于空链表的添加
- 对于非空链表的添加
- add(int index, E element)
- node(index)
- linkBefore
- 头结点处添加:
- 中间位置添加
- get(int index)
- add(E e)
- Deque体系下的方法:
- 作为队列
- 作为栈
- List体系下的方法:
- 总结
前言
本文基于jdk1.8
书接上回,在简单介绍ArrayList的时候,提到了ArrayList实现了RandomAccess接口,拥有随机访问的能力,当时说到了这个接口配合LinkedList理解更容易。今天就来还愿了,开始阅读LinkedList。
LinkedList也算我们比较常用的几个集合之一了,对普通程序员来说,
List list1 = new ArrayList()List list2 = new LinkedList(),该怎么选择?
其实二者最大的区别在于实现方式的不同,只看名称我们也能知道, ArrayList基于数组,而LinkedList基于链表,所以关键在于数组和链表有啥区别。
说到这,是不是又说明了一个很重要的道理,基础,基础,基础。如果想成为一个真正的程序员,不管你是科班还是半路出家,都要下功夫夯实基础。
说回正题,ArrayList基于数组,查找快(按索引查找),增删慢;LinkedList基于链表,增删快,查找慢。但这只是相对的,仅仅知道这两点,远远不够,所以,继续往下看。
类签名
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable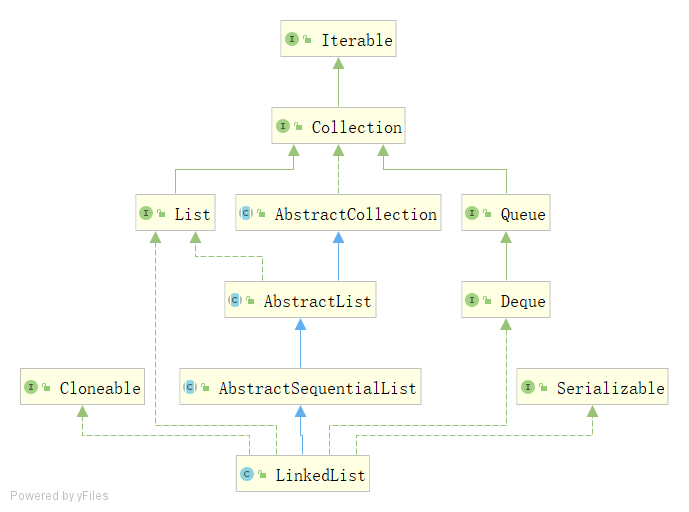
鉴于前一篇有很多遗漏,这里多说明一下:
泛型
集合类在1.5开始的版本中都采用了泛型,也就是
不用泛型,List list1 = new LinkedList();此时默认类型是Object,也就是可以添加任意类型元素,在取出元素时,就需要强制类型转换,增加了出错几率。
使用泛型,List
因为我们使用集合绝大部分情况都是希望存储同一种类型,所以使用泛型(提前声明类型)很重要。这里也体现了一种思想:错误越早暴露越好。
Serializable和Cloneable
实现Cloneable, Serializable接口,具有克隆和序列化的能力。
Deque
实现了Deque接口, 而Deque接口又继承了Queue接口,这也意味着LinkedList可以当队列使用,实现"先进先出"。
List和AbstractList
在上一篇文章中,有一个细节没有说到,可能很多人也有疑问, 为啥抽象类AbstractList已经实现了List接口,ArrayList在继承AbstractList的同时还要再次实现List接口?换到今天的主角,LinkedList继承了AbstractSequentialList,而AbstractSequentialList继承了AbstractList,为啥LinkedList还要单独实现List接口?
在Stack Overflow上看到两个回答:
一位网友说问过了设计这个类的作者本人,作者本人表示这是当时设计时的一个缺陷,就一直遗留下来了。(当然,我个人觉得这个说法有待考证)。
第二位网友举例表明了不直接再次实现List接口,使用代理时可能会出现意想不到的结果。(从实际的角度看有道理,但是细想之下集合类在jdk1.2已经出现,代理类出现在 1.3,逻辑上有点疑问。)
我个人的理解:
大神在设计集合类的时候充分考虑到了将来优化时的情况。
具体来讲,这里主要在于如何理解接口和抽象类的区别,尤其是在java8之前。接口是一种规范,方便规划体系,抽象类已经有部分实现,更多的是帮助我们减少重复代码,换言之, 这里的抽象类就相当于一个工具类,只不过恰好实现了List接口,而且鉴于java单继承,抽象类有被替换的可能。
在面向接口编程的过程中,List list= new LinkedList();如果将来LinkedList有了更好的实现,不再继承AbstractSequentialList抽象类,由于本身已经直接实现了List接口,只要内部实现符合逻辑,上述旧代码不会有问题。相反,如果不实现List,去除继承AbstractSequentialList抽象类,上述旧代码就无法编译,也就无法"向下兼容"。
RandomAccess接口(没实现)
LinkedList并没有实现RandomAccess接口,实现这个接口的是ArrayList,之所以放在这里是为了对比。
注意,这里说的随机访问的能力指的是根据索引访问,也就是list接口定义的E get(int index)方法,同时意味着ArrayList和LinkedList都必须实现这个方法。
回到问题的本质,为啥基于数组的ArrayList能随机访问,而基于链表的LinkedList不具备随机访问的能力呢?
还是最基础的知识:数组是一块连续的内存,每个元素分配固定大小,很容易定位到指定索引。而链表每个节点除了数据还有指向下一个节点的指针,内存分配不一定连续,要想知道某一个索引上的值,只能从头开始(或者从尾)一个一个遍历。
RandomAccess接口是一个标记接口,没有任何方法。唯一的作用就是使用instanceof判断一个实现集合是否具有随机访问的能力。
List list1 = new LinkedList();if (list1 instanceof RandomAccess) { //...}可能看到这里还是不大明白,不要紧,这个问题的关键其实就是ArrayList和LinkedList对List接口中get方法实现的区别,后文会专门讲到。
变量
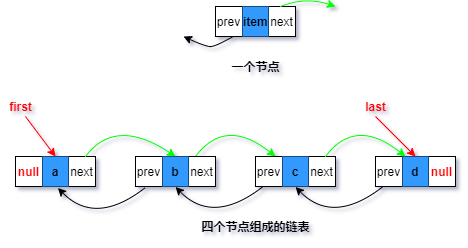
//实际存储元素数量transient int size = 0;/** * 指向头节点,头结点不存在指向上一节点的引用 * * Invariant: (first == null && last == null) || * (first.prev == null && first.item != null) */transient Node<E> first;/** * 指向尾节点,尾节点不存在指向下一节点的引用 * Invariant: (first == null && last == null) || * (last.next == null && last.item != null) */transient Node<E> last;//节点类型,包含存储的元素和分别指向下一个和上一个节点的指针private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; }}注意这里的节点类型,可以看出,LinkedList实现基于双向链表。为啥用不直接用单向链表一链到底呢?最主要的原因是为了查找效率,前面说到链表的查找效率比较低,如果是单向链表,按索引查找时,不管索引处于哪个位置,只能从头开始,平均需要N次;若是双向链表,先判断索引处于前半部分还是后半部分,再决定从头开始还是从尾开始,平均需要N/2次。当然,双向链表的缺点就是需要的存储空间变大,这从另一个方面体现了空间换时间的思想。
上述两个变量,first和last,其本质是指向对象的引用,和Student s=new Student()中的s没有区别,只不过first一定指向链表头节点,last一定指向链表尾节点,起到标记作用,让我们能够随时从头或者从尾开始遍历。
构造函数
//空参构造public LinkedList() {}//通过指定集合构造LinkedList, 调用addAll方法public LinkedList(Collection<? extends E> c) { this(); addAll(c);}常用方法
常用方法比较多(多到一张图截不下),这里主要分两类,一类是List体系,一类是Deque体系.
List体系下的方法:
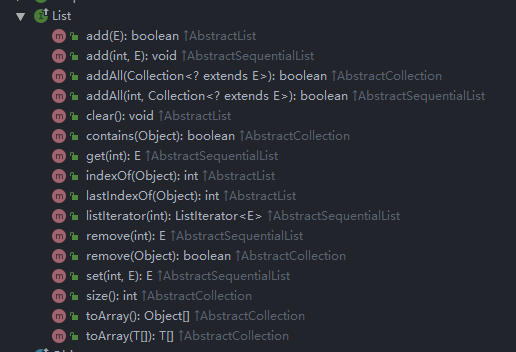
这里主要看两个,add,get
add(E e)
添加元素到链表末尾,成功则返回true
//添加元素到链表末尾,成功则返回truepublic boolean add(E e) { linkLast(e); return true;}void linkLast(E e) { //1.复制一个指向尾节点的引用l final Node<E> l = last; //2.将待添加元素构造为一个节点,prev指向尾节点 final Node<E> newNode = new Node<>(l, e, null); //3.last指向新构造的节点 last = newNode //4.如果最初链表为空,则将first指向新节点 if (l == null) first = newNode; //5.最初链表不为空,则将添加前最后元素的next指向新节点 else l.next = newNode; //存储的元素数量+1 size++; //修改次数+1 modCount++;}关键在于linkLast(E e)方法,分两种情况,最初是空链表添加元素和最初为非空链表添加。
这里涉及到的知识很基础,还是链表的基本操作,但是单纯用语言很难描述清楚,所以画个简图表示一下(第一次画图,没法尽善尽美,将就一下吧)
linkLast(E e)方法
双向链表的基本形式
对于空链表的添加
对应linkLast(E e)方法注释1、2、3、4
空链表,没有节点,意味着first和last都指向null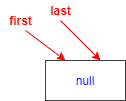
1.复制一个指向尾节点的引用l(蓝色部分)
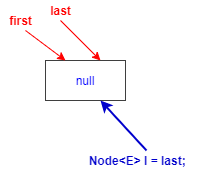
此时复制的引用l本质也指向了null
2.将待添加元素构造为一个节点newNode,prev指向,也就是null
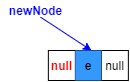
3.last指向新构造的节点(红色部分)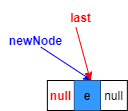
4.最初链表为空,将first指向新节点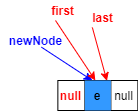
此时,first和last均指向唯一非空节点,当然引用newNode依然存在,但是已经没有意义。
对于非空链表的添加
对应linkLast(E e)方法注释1、2、3、5
1.复制一个指向尾节点的引用l(蓝色部分)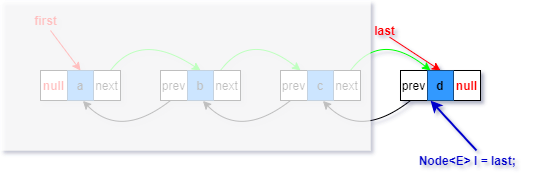
2.将待添加元素构造为一个节点newNode,prev指向尾节点(蓝色部分)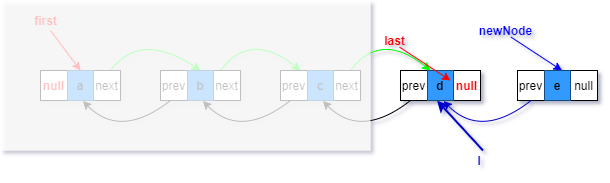
3.last指向新构造的节点(红色部分)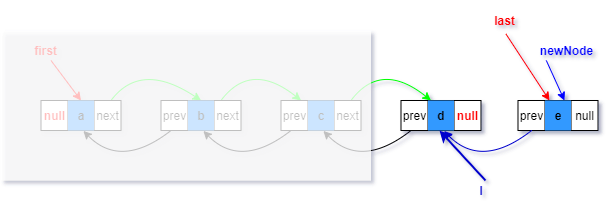
5.将添加前最后元素的next指向新节点(绿色部分)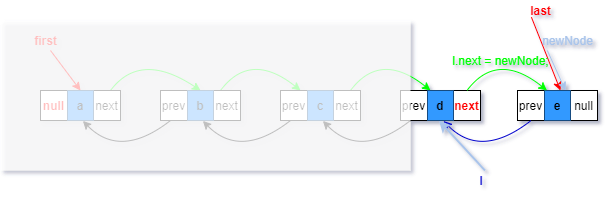
此时,引用newNode和l引用依然存在,但是已经没有意义。
add(int index, E element)
将元素添加到指定位置
public void add(int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); else linkBefore(element, node(index));}可以看出,该方法首先检查指定索引是否符合规则,也就是在index >= 0 且 index <= size;
如果index==size,则相当于直接在链表尾部插入,直接调用linkLast方法;
以上不满足,调用linkBefore方法,而linkBefore中调用了node(index)。
node(index)
node(index)作用是返回指定索引的节点,这里用到了我们前面说到的一个知识,先判断索引在前半部分还是在后半部分,再决定从头还是从尾开始遍历。
Node<E> node(int index) { // assert isElementIndex(index); //如果索引在前半部分,则从头结点开始往后遍历 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { //如果索引在后半部分,则从尾向前遍历 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; }}linkBefore
回过头来看linkBefore,参数分别为待插入的元素,以及指定位置的节点
void linkBefore(E e, Node<E> succ) { // assert succ != null; //1.复制指向目标位置的上一个节点引用 final Node<E> pred = succ.prev; //2.构造新节点,prev指向目标位置的上一个节点,next指向原来目标位置节点 final Node<E> newNode = new Node<>(pred, e, succ); //3.原来节点prev指向新节点 succ.prev = newNode; //4.如果插在头结点位置,则first指向新节点 if (pred == null) first = newNode; //5.非头节点,目标位置上一节点的next指向新节点 else pred.next = newNode; size++; modCount++;}上述过程可以看出,关键过程在于linkBefore方法,我们同样画图表示:
头结点处添加:
1.复制指向目标位置的上一个节点引用
Node<E> pred = succ.prev;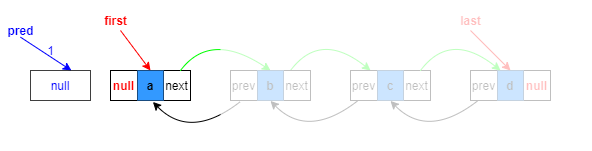
本质是指向null
2.构造新节点,prev指向目标位置的上一个节点,next指向原来目标位置节点
Node<E> newNode = new Node<>(pred, e, succ);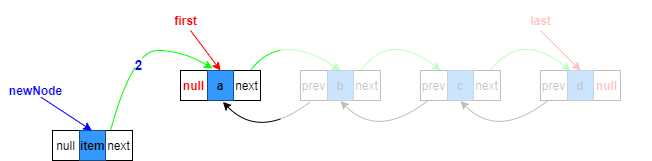
3.目标节点的prev指向待添加新节点
succ.prev = newNode;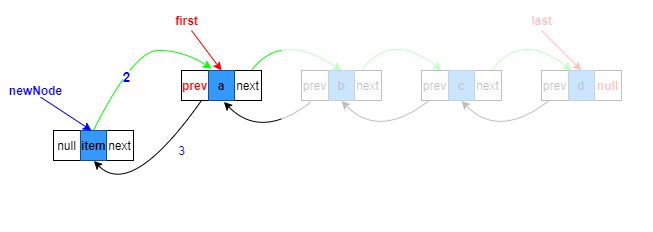
4.first指向新节点
first = newNode;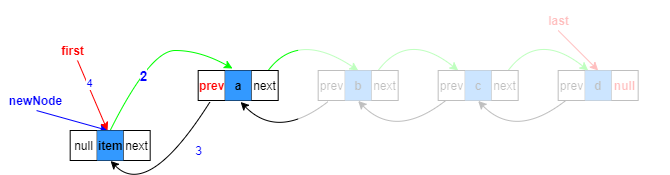
中间位置添加
如图,假设指定添加到第三个节点,即index=2,则第二个和第三个节点之间必须有断开的过程。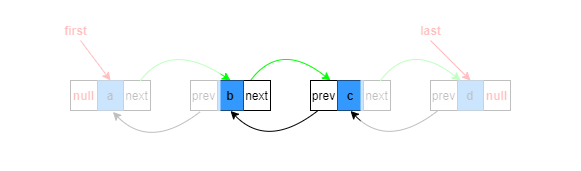
1.复制指向目标位置的上一个节点引用,也就是第二个节点
Node<E> pred = succ.prev;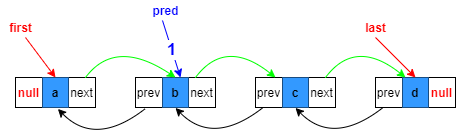
2.构造新节点,prev指向复制的上一个节点,next指向原来目标位置上的节点
Node<E> newNode = new Node<>(pred, e, succ);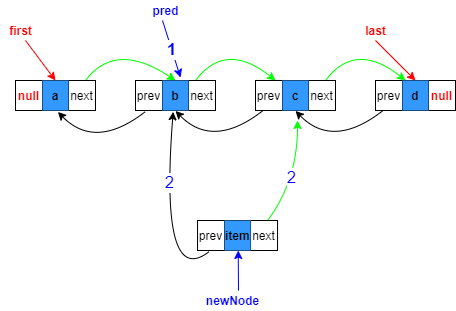
3.目标节点的prev指向待添加新节点
succ.prev = newNode;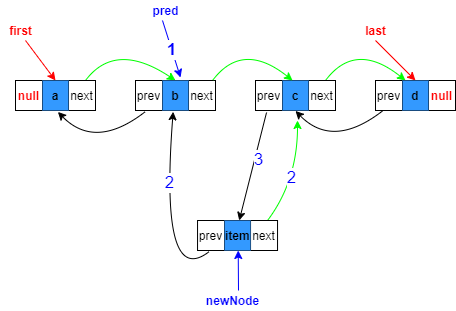
5.目标位置上一节点的next指向新节点
pred.next = newNode;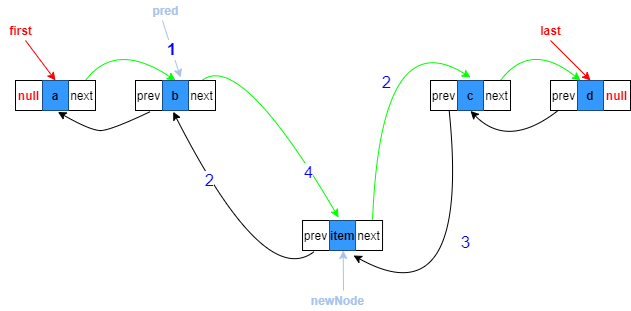
get(int index)
public E get(int index) { checkElementIndex(index); return node(index).item;}get方法是按索引获取元素,本质调用node(index),上一部分已经提到了这个方法,虽然双向链表在一定程度上提高了效率,由N减少到N/2,但本质上时间复杂度还是N的常数倍,所以轻易不要用这个方法,在需要随机访问的时候应当使用ArrayList,在需要遍历访问以及增删多查找少的时候考虑LinkedList。之所以要有这个方法是由List接口指定,这个方法也是LinkedList没有实现RandomAccess接口的原因之一。
Deque体系下的方法:
当我们把LinkedList当队列和栈使用时,主要用到的就是Deque体系下的方法。
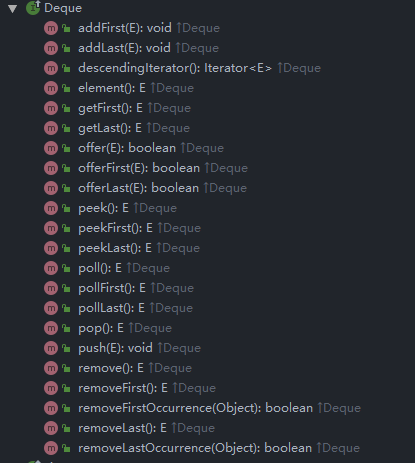
如果稍微细看一下,会发现上述很多方法基本是重复的,比如push(E e)其实就是调用了addFirst(e),
addFirst(e)也是直接调用了linkFirst(e);pop()就是直接调用了removeFirst();
为啥搞这么麻烦,一个方法起这么多名称?
其实是因为从不同角度来看LinkedList时,它具有不同的角色。可以说它哪里都能添加,哪里都能删除。
具体使用时建议仔细看下对应注释。
作为队列
队列的基本特点是"先进先出",相当于链表尾添加元素,链表头删除元素。
对应的方法是offer(E e),peek(),poll()
public boolean offer(E e) { return add(e);}public boolean add(E e) { linkLast(e); return true;}可以看出offer方法的本质还是在链表末尾添加元素,linkLast(e)方法前面已经讲到。
/*** Retrieves, but does not remove, the head (first element) of this list.** @return the head of this list, or {@code null} if this list is empty* @since 1.5*/public E peek() { final Node<E> f = first; return (f == null) ? null : f.item; }peek()方法返回队列第一个元素,但是不删除元素。也就是说多次peek得到同一个元素。
/** * Retrieves and removes the head (first element) of this list. * * @return the head of this list, or {@code null} if this list is empty * @since 1.5 */public E poll() { final Node<E> f = first; return (f == null) ? null : unlinkFirst(f);}poll() 方法返回队列第一个元素的同时并将其从队列中删除。也就是多次poll得到不同元素。
显然poll方法更符合队列的概念。
这里没有详细解说删除相关的方法,是因为如果前面的添加方法细看了,删除方法也很简单,无非是越过被删除的元素连接指针,这里没必要浪费篇幅。不妨自己画一下,有助于理解。
作为栈
栈的基本特点是"先进后出",相当于链表头部添加元素,头部删除元素。
对应的方法是push(E e)和pop()。
public void push(E e) { addFirst(e);}public void addFirst(E e) { linkFirst(e); }可以看出,push是在调用addFirst,进而调用linkFirst(e),而在头部添加元素,add(int index, E element)方法处已经讲到了,大体只是方法名不一样而已。
public E pop() { return removeFirst();}pop()方法返回并删除第一个元素。
总结
这篇文章主要讲了LinkedList相关的最基本的内容,更多的是回顾一些基础知识,既有java相关的,也有最基础数据结构的知识,比如链表相关的操作。第一次画图来说明问题,有时候真的是一图胜千言。写到这里最大的感受是基础很重要,它决定了你能走多远。
希望我的文章能给你带来一丝帮助!
原文转载:http://www.shaoqun.com/a/488016.html
丰趣海淘:https://www.ikjzd.com/w/1716
new old stock:https://www.ikjzd.com/w/2341
淘粉8:https://www.ikjzd.com/w/1725.html
通过阅读LinkedList,回顾java和链表相关的基础知识,画图表示,一图胜千言。目录前言类签名泛型Serializable和CloneableDequeList和AbstractListRandomAccess接口(没实现)变量构造函数常用方法List体系下的方法:add(Ee)linkLast(Ee)方法双向链表的基本形式对于空链表的添加对于非空链表的添加add(intindex,Eele
mail.ru:https://www.ikjzd.com/w/2232
灯塔计划:https://www.ikjzd.com/w/1281
深圳西冲海滩露营怎么样?西冲露营地点怎么选?:http://tour.shaoqun.com/a/38952.html
广州长隆大马戏的票价是多少?:http://tour.shaoqun.com/a/2918.html
深圳圣诞节哪里能看到人造雪?:http://tour.shaoqun.com/a/1344.html
No comments:
Post a Comment