
一杯茶一包烟,一个Bug改一天!!相信很多"爱码仕"都曾经对着电脑几个小时就为改一个bug,最后是在美团小哥指点下修复的。他曾经也是王者,不为别的,就是喜欢送外卖锻炼身体还能远离产品经理和测试。
言归正传,本文还是个不正经的多线程教程,呃...也算不上教程,个人笔记吧。主要解答一下上文留下的两个问题:缓存一致性协议再详细说一下JMM(Java Memory Mode),最后再讲一下Java对象在堆空间的布局。等等,哪里不对,这不是讲多线程的文章吗?怎么没内味了?稍安勿躁,多线程要写滴,但是写之前,还是要了解一下更深层次的东西,深入原理,方可百战不殆,阿弥陀佛~~
缓存一致性协议
话不多说,咱先拆解一下这7个字。
缓存:不用说了吧,就是为了让读更快嘛。有客户端缓存、服务端缓存、数据库缓存、本地缓存、CDN缓存、分布式缓存、CPU缓存等等等等,而本文主要是针对CPU缓存来介绍的,其他缓存只要你关注(都黑体加粗了,给个三连吧),我会快马加鞭的写。
一致性:在CPU缓存中,这个一致性就是强调在多线程并发场景下CPU的本地缓存和主存中数据的一致性,而这个数据就是指多个线程都要用到的共享数据,即我们常说的临界资源。
协议:更简单了,就是认为规定的东西,让硬件软件都必须准守的规则,让它们必须在给定的框框里工作运行。
到这里就拆解完成了,那么有哪些缓存一致性协议呢?它们由什么来确定的呢?又和我写CRUD有啥关系呢?
首先,缓存一致性协议有很多种,比如:MESI(最常见)、MSI、MOSI、FireFly等等,欢迎大佬们评论区补充。而具体使用哪一种,其实是由CPU架构决定的,也就是说安心写BUG吧,开发人员无需考虑CPU架构的问题,因为我们有JVM(Java Virtual Machine),屏蔽了平台间的差异性解决了跨平台的问题,哪有什么岁月静好,不过是有人在负重前行罢了。但是你要知道这些东西,毕竟我们是互联网的弄潮儿,giao~~~~
接下来还是上图: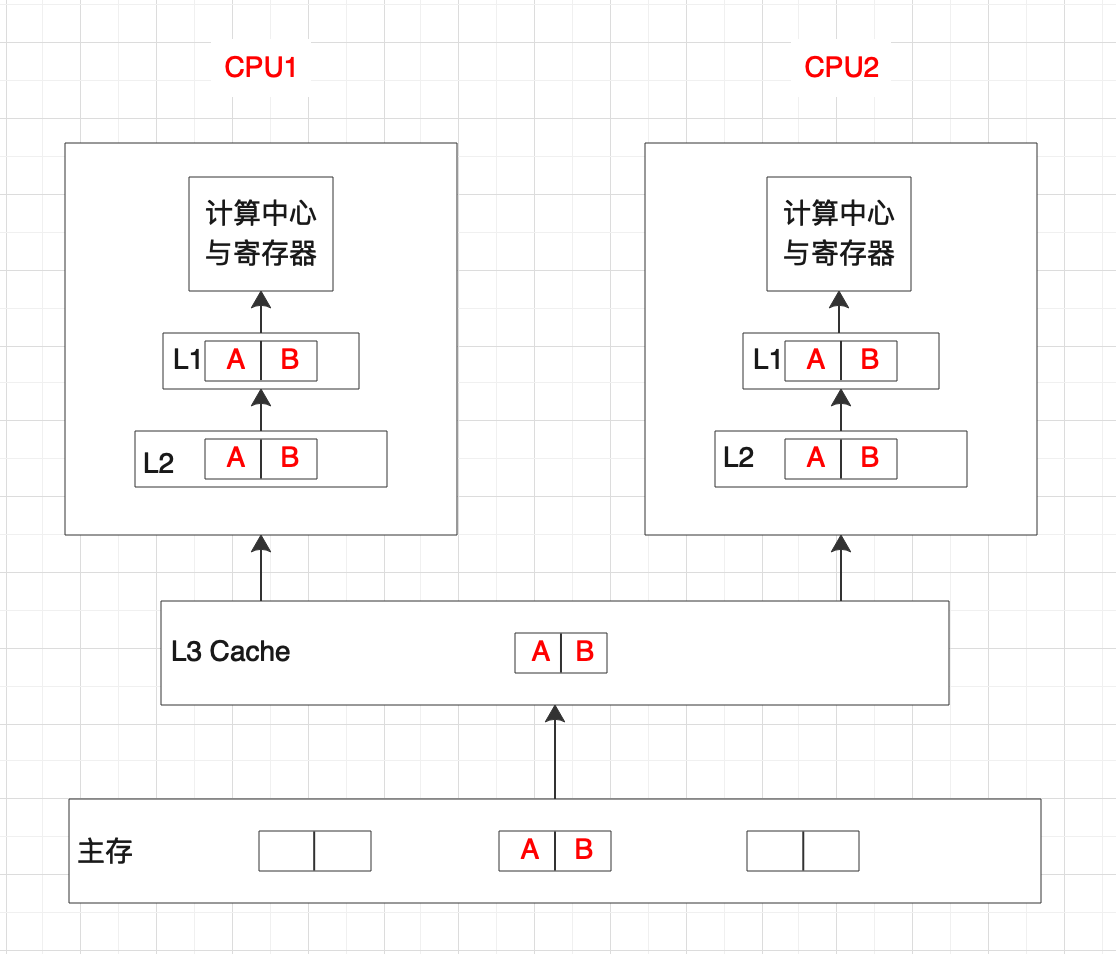
这样更直观一些,当CPU1缓存行中有A,B且刚好要对其中的A做修改,CPU2也缓存了同样的缓存行且对A图谋不轨。那这时候就需要工程师来制定协议了:让多颗CPU在同时使用共享数据时,保持数据的一致性,即缓存一致性协议。协议类型前边已经说过了,不同的类型有不同的解决方案。可以通过监听CPU总线的方式实现,也可以在当CPU1修改A时强制其它所有CPU中含有A的缓存行同步更新。具体平台的实现还是看CPU架构
缓存行又是个什么东西?
CPU为了最求极致的代码运行效率。当从内存中读取数据时,并不仅仅只读自己想要的部分。而是读取足够的字节来填入高速缓存行。缓存行的大小通常为2的整数幂,常见的为32字节和64字节。
缓存行带来的是更加高效的数据加载,但同时也带来了缓存行伪共享的问题,还是按上面的图来说:当CPU1只使用A值,CPU2只使用B值,但是由于缓存行的存在且A,B两个值相邻,那么无论哪个CPU修改了自己需要的值,都需要通过总线通知对方做更新操作,这样就影响了效率。解决方案也很简单: 以64字节长度缓存行为例,在创建A或者B的时候,在值的前后分别补齐7个Long类型的"占位符",你问为什么是7个?因为7个Long类型是7*8=56个字节,这样填充之后,无论怎么加载A,B都不会出现在同一个缓存行中,也就规避了伪共享的问题。有关缓存行以及伪共享的额详细介绍请看:https://www.jianshu.com/p/e338b550850f 和 https://blog.csdn.net/u010983881/article/details/82704733
最后补充一张我的图如下: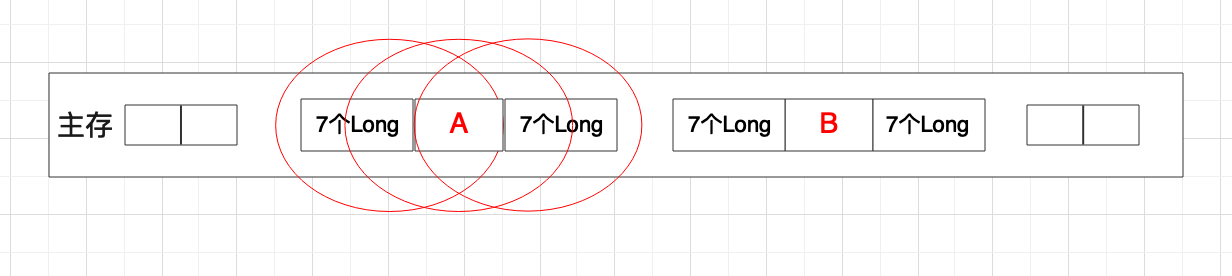
红色圈代表一个64字节缓存行大小,这样无论怎么加载,都不会存在A,B同时被加载到同一缓存行中。
JMM详解
在上一篇文章中,大概说了JMM是个什么东西,也丢了一张图进去。那么这回我们就再详细一点介绍下什么是JMM(Java Memory Mode),还是要强调一下,它是一种抽象层的规范,而且一定要跟Java运行时内存空间区分开来,两者有联系,但也有很大区别。再把上节的图拿过来说吧(有兴趣可以扫码关注不迷路):
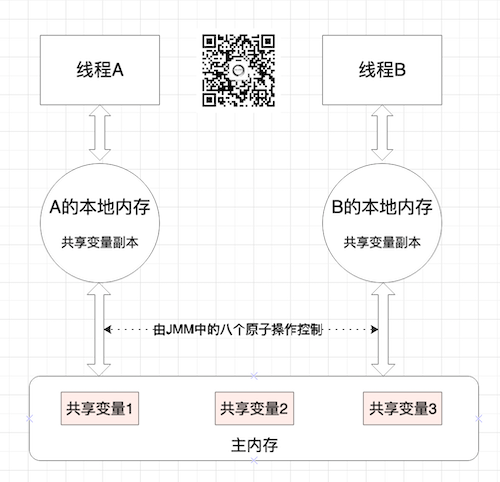
一句话来说就是:JMM是一种java虚拟机规范(看见没,又是规范,前辈们规定的),其目的是屏蔽掉各种硬件和操作系统的内存访问差异,制定了虚拟机与计算机内存交互要遵循的规章制度,让咱们工程师兄弟姐妹们安心写BUG。
从图里可以看出,在JMM的规范中,存在本地工作内存和主内存两个概念,前者是线程私有的后者是线程间共享的,此时你是不是想到了JVM里面的堆、栈、方法区、计数器、常量池等等?没想到就面壁去(看《深入理解Java虚拟机》)。没错,他们之间存在是有若无的关系,但却不是一个层次的概念。因为JVM里面对内存空间的划分是确确实实存在的,而JMM仅仅是抽象规范,指导思想而已。等多线程写完了,再写JVM的文章,会详细介绍内存区域划分。
回到主题接着说JMM,还是抛出以下几个个问题:
什么是工作内存?
存放当前方法的所有本地变量信息,线程中的本地变量对其他线程是不可见的,不同的线程即使用到的是主内存中的同一个共享数据,也都只是拷贝一个副本在自己的工作内存中做操作,最后刷新回主存。因此线程本地内存中的数据是线程私有且线程安全的(其他线程看都看不到能不安全吗?)。
什么是主内存?
主要是存放Java的实例对象,也包括了一些共享的类的信息、常量、静态变量等,被定义为多线程共享的区域。
JMM又是如何规范数据访问的?
线程的运行离不开数据,主内存与工作内存之间的具体交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步到主内存之间的实现细节,JMM定义了八种原子操作来完成。来,我把上面的图升级一下。然后再看个表格。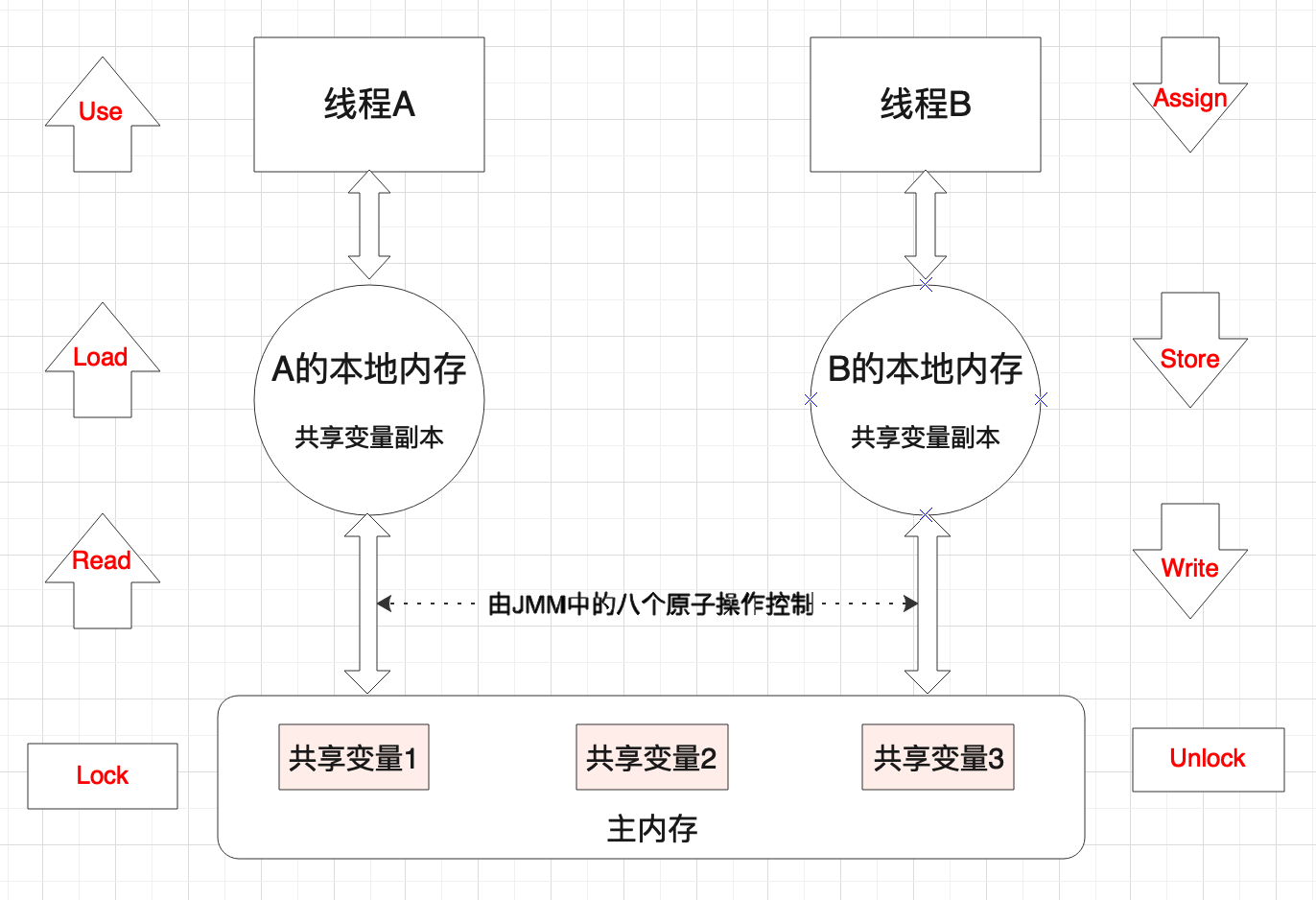
| 原子操作 | 说明 |
|---|---|
| lock(锁定) | 作用于主内存变量,标识变量为某个线程的独享状态 |
| read(读取) | 作用于主内存变量,将变量值从主存传输到线程的工作内存中 |
| load(载入) | 作用于工作内存变量,将read操作得到的变量值放入工作内存的变量副本中 |
| use (使用) | 作用于工作内存变量,把工作内存中的一个变量值传递给执行引擎 |
| assign(赋值) | 作用于工作内存变量,它把一个从执行引擎接收到的值赋值给工作内存的变量 |
| store (存储) | 作用于工作内存变量,把工作内存中的一个变量值传送到主内存中,以便随后的write的操作 |
| write (写入) | 作用于主内存变量,把store操作从工作内存中一个变量的值传送到主内存的变量中 |
| unlock(解锁) | 作用于主内存变量,把一个处于锁定状态的变量释放出,释放后的变量才可以被其他线程锁定 |
总结一下:前面说的,其实在开发过程中99%的开发人员都用不到,有用得到的大佬,可以留言讨论一波。Volatile通过禁止指令重排以及CPU总线监听机制,解决可见性和有序性问题,Synchronized解决了原子性问题,但是其内部还是存在编译优化的操作,这个后续在Synchronized的专题文章中会详细介绍。关于JMM更多更深入的文章请看 id="java对象在堆空间的排兵布阵">Java对象在堆空间的排兵布阵
讲多线程,为啥要说对象在堆空间的排布呢?为了知己知彼,也是为了方便理解Synchronized是如何在底层加锁的。而且,不管你会不会,面试的时候肯定问,所以学不学呢?哈哈哈哈...
我们每次新建的对象实例,其实它在堆空间中是被分为三个部分:对象头、实例数据以及对象填充(是不是很熟悉?前面在讲CPU缓存一致性协议的时候有说到缓存行对齐)。所以,很多知识学着学着,就都对上了,从很多CPU级别的微观协议,就能推导出宏观的微服务级别的协议。扯远了,接着说正题!!!对Java象头其实又分为了Mark Word、Class Point和数组长度三部分。
对象头(Object Head)
Mark Word这部分数据的大小为64位,其中数据包含HashCode、GC分代年龄、偏向锁位,锁标志位等,如果是偏向锁还会记录偏向锁偏向的线程ID。而我们熟知的(如果你还不熟知,可以Google一下,或者等我的文章也行)锁升级,锁撤销等等一系列操作,都会在对象头中找到端倪,状态都是一一对应的。你说,这些如果滚瓜烂熟了,还会害怕面试官吗?当然,今天不展开说了,这里只讲布局。
Class Point可以理解为就是一个指针,指向描述这个对象类型的class。在64位系统中占64位,也就是8个字节,而在32位系统只占4个字节。但是为了节省空间(这些研究人员,真是把性能优化到极致,到了我这却....惨不忍睹啊!!!),在JDK1.6以后默认开启指针压缩-XX:+UseCompressedClassPointers,64位系统的也是4位比如问候后边的Student student = new Student();那么这个Class Point就是指向的Student.class,因为这个class的内部具体描述了当前这个对象的内部属性及方法。
数组长度(Array Length)这个好理解,就是如果对象是一个数组对象,那么这里存储的就是数组的长度。非数组对象是没有这块内存区域的,这是在分配内存空间的时候就已经确定了的。
实例数据(Instance Data)
这个也简单,就是你创建的对象真正存储的信息,包括自己内部定义的属性和从父类继承的属性。常见的就是一些String、Integer啥的。这个没啥特别的
对象填充(Padding)
可以理解为占位符,还是基于虚拟机的一些规范,因为Java都是自动内存管理,为了方便管理,生成的对象占用的空间必须为8字节的整数倍,如果不足整数倍就补空白空间,避免在垃圾回收的时候产生不必要的内存空间碎片,增加垃圾回收的压力。
注:以上数据均默认在64位系统中,32位系统,看官们可以自己测一下,虚拟机均指HotSport
下面用一张图,展示一下对象在堆空间的排布状况: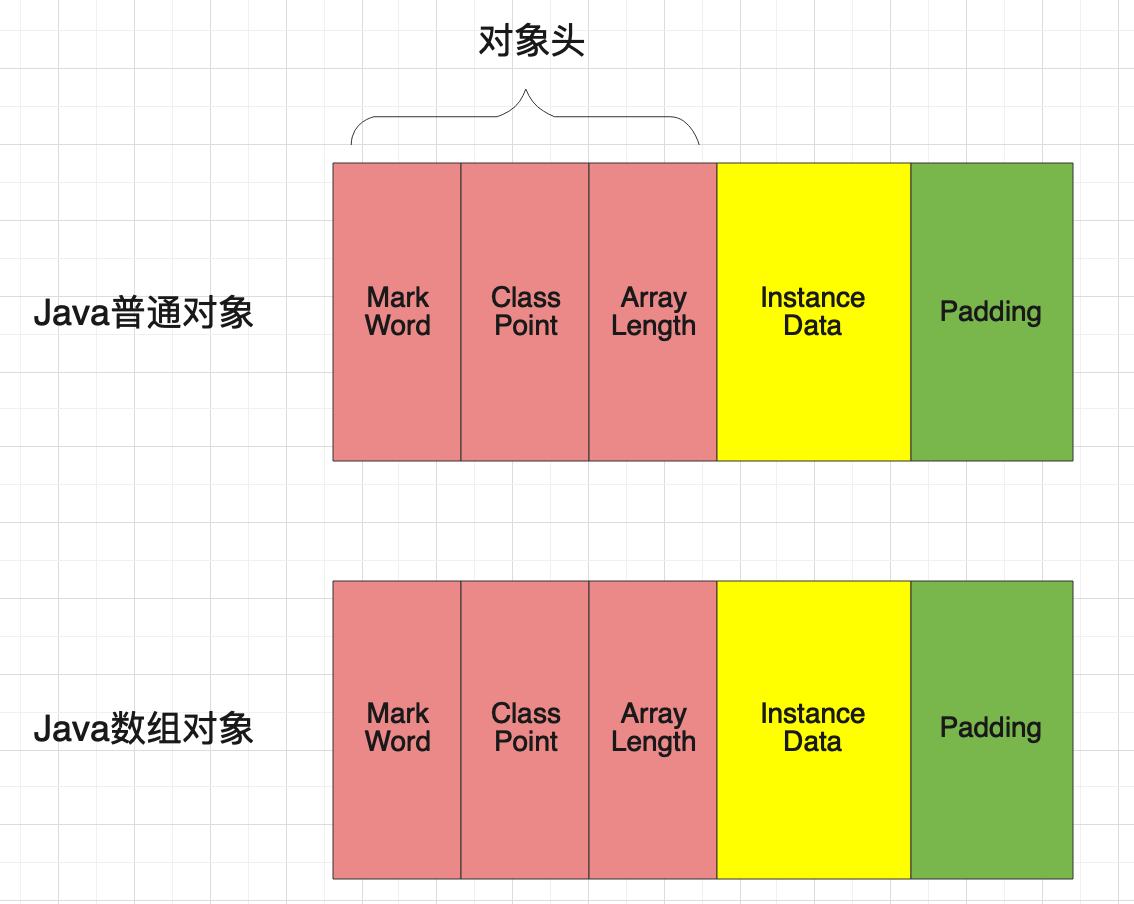
嗯~nice,可是口说无凭,咱们上代码,在new个阿猫阿狗的看看到底各个部分占用的空间情况吧。
引入依赖jol-core
openjdk提供的依赖jar,可以协助我们查看堆中对象各个模块占用的空间大小
<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> <version>0.9</version></dependency>上代码
/** * FileName: JavaObjectMode * Author: RollerRunning * Date: 2020/11/28 7:12 PM * Description:查看Java对象在内存中的布局 */public class JavaObjectMode { public static void main(String[] args) { //创建对象 Student student = new Student(); // 获得对象布局内容 String s = ClassLayout.parseInstance(student).toPrintable(); // 打印对象布局 System.out.println(s); }}class Student{ private String name; private String address; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getAddress() { return address; } public void setAddress(String address) { this.address = address; }}上结果
大家有兴趣也可以CV一下,自己看看。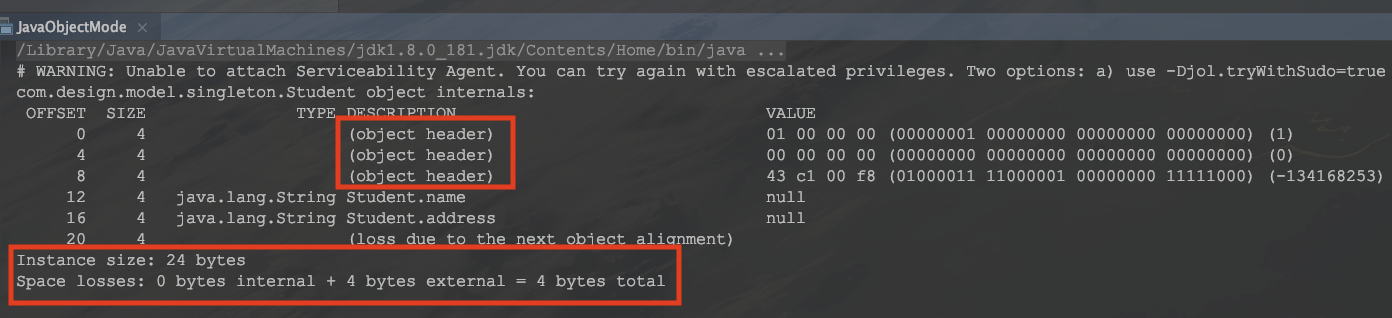
那结果有了,重点已经圈出来了,分析一波吧?别往下看了,自己先看看,再想十秒钟。1,2,3,4,5,6,7,8,9,10。好,分析开始!
第一个圈,圈出来的是对象头的内容,依次往下是对象的值和一行英文(loss due to the next object alignment)表示对齐填充,增加了一个4字节的填充,刚好是24字节,能够被8整除,满足了虚拟机规范,这就是对齐填充价值所在。而后边的红圈圈则是当前对象的一个概况,没啥意义,就是想画个圈(画错了又懒得改而已.....),回到第一个圈圈对象头,前两行一共是8字节,64位的Mark Word。而OFFSET从8开始size为4的那一行就是前面说的Class Point。
好了,我肝完了,最后卖个关子,请注意一下最后一列的前三行,下一篇文章会根据这三行结合Synchronized关键字展开说。
最后,感谢各位观众老爷,还请三连!!!
更多文章请扫码关注或微信搜索Java栈点公众号!

原文转载:http://www.shaoqun.com/a/493337.html
急速:https://www.ikjzd.com/w/1861
沃尔玛:https://www.ikjzd.com/w/220
易联通:https://www.ikjzd.com/w/1854.html
一杯茶一包烟,一个Bug改一天!!相信很多"爱码仕"都曾经对着电脑几个小时就为改一个bug,最后是在美团小哥指点下修复的。他曾经也是王者,不为别的,就是喜欢送外卖锻炼身体还能远离产品经理和测试。言归正传,本文还是个不正经的多线程教程,呃...也算不上教程,个人笔记吧。主要解答一下上文留下的两个问题:缓存一致性协议再详细说一下JMM(JavaMemoryMode),最后再讲一下Java对象在堆空间的
二类电商:二类电商
patpat:patpat
阿里国际站迎战3月新贸节,开启直通车春节不打烊活动:阿里国际站迎战3月新贸节,开启直通车春节不打烊活动
口述:恋爱五年他向我提出"试婚"试婚五年恋爱:口述:恋爱五年他向我提出"试婚"试婚五年恋爱
这样玩转亚马逊广告动态竞价,第二天就出了186单!:这样玩转亚马逊广告动态竞价,第二天就出了186单!
No comments:
Post a Comment