某一天,在逛某金的时候突然看到这篇文章,前端大文件上传,之前也研究过类似的原理,但是一直没能亲手做一次,始终感觉有点虚,最近花了点时间,精(熬)心(夜)准(肝)备(爆)了个例子,来和大家分享。
本文代码:github

问题
Knowing the time available to provide a response can avoid problems with timeouts. Current implementations select times between 30 and 120 seconds
https://tools.ietf.org/id/draft-thomson-hybi-http-timeout-00.html
如果一个文件太大,比如音视频数据、下载的excel表格等等,如果在上传的过程中,等待时间超过30 ~ 120s,服务器没有数据返回,就有可能被认为超时,这是上传的文件就会被中断。
另外一个问题是,在大文件上传的过程中,上传到服务器的数据因为服务器问题或者其他的网络问题导致中断、超时,这是上传的数据将不会被保存,造成上传的浪费。
原理
大文件上传利用将大文件分片的原则,将一个大文件拆分成几个小的文件分别上传,然后在小文件上传完成之后,通知服务器进行文件合并,至此完成大文件上传。
这种方式的上传解决了几个问题:
- 文件太大导致的请求超时
- 将一个请求拆分成多个请求(现在比较流行的浏览器,一般默认的数量是6个,同源请求并发上传的数量),增加并发数,提升了文件传输的速度
- 小文件的数据便于服务器保存,如果发生网络中断,下次上传时,已经上传的数据可以不再上传
实现
文件分片
File接口是基于Blob的,因此我们可以将上传的文件对象使用slice方法 进行分割,具体的实现如下:
export const slice = (file, piece = CHUNK_SIZE) => { return new Promise((resolve, reject) => { let totalSize = file.size; const chunks = []; const blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice; let start = 0; const end = start + piece >= totalSize ? totalSize : start + piece; while (start < totalSize) { const chunk = blobSlice.call(file, start, end); chunks.push(chunk); start = end; const end = start + piece >= totalSize ? totalSize : start + piece; } resolve(chunks); });};然后将每个小的文件,使用表单的方式上传
_chunkUploadTask(chunks) { for (let chunk of chunks) { const fd = new FormData(); fd.append('chunk', chunk); return axios({ url: '/upload', method: 'post', data: fd, }) .then((res) => res.data) .catch((err) => {}); }}后端采用了express,接收文件采用了[multer](https://github.com/expressjs/multer)这个 库
multer上传的的方式有single、array、fields、none、any,做单文件上传,采用single和array皆可,使用比较简便,通过req.file 或 req.files来拿到上传文件的信息
另外需要通过disk storage来定制化上传文件的文件名,保证在每个上传的文件chunk都是唯一的。
const storage = multer.diskStorage({ destination: uploadTmp, filename: (req, file, cb) => { // 指定返回的文件名,如果不指定,默认会随机生成 cb(null, file.fieldname); },});const multerUpload = multer({ storage });// routerrouter.post('/upload', multerUpload.any(), uploadService.uploadChunk);// serviceuploadChunk: async (req, res) => { const file = req.files[0]; const chunkName = file.filename; try { const checksum = req.body.checksum; const chunkId = req.body.chunkId; const message = Messages.success(modules.UPLOAD, actions.UPLOAD, chunkName); logger.info(message); res.json({ code: 200, message }); } catch (err) { const errMessage = Messages.fail(modules.UPLOAD, actions.UPLOAD, err); logger.error(errMessage); res.json({ code: 500, message: errMessage }); res.status(500); }}上传的文件会被保存在uploads/tmp下,这里是由multer自动帮我们完成的,成功之后,通过req.files能够获取到文件的信息,包括chunk的名称、路径等等,方便做后续的存库处理。
为什么要保证chunk的文件名唯一?
- 因为文件名是随机的,代表着一旦发生网络中断,如果上传的分片还没有完成,这时数据库也不会有相应的存片记录,导致在下次上传的时候找不到分片。这样的后果是,会在
tmp目录下存在着很多游离的分片,而得不到删除。 - 同时在上传暂停的时候,也能根据chunk的名称来删除相应的临时分片(这步可以不需要,
multer判断分片存在的时候,会自动覆盖)
如何保证chunk唯一,有两个办法,
- 在做文件切割的时候,给每个chunk生成文件指纹 (
chunkmd5) - 通过整个文件的文件指纹,加上chunk的序列号指定(
filemd5+chunkIndex)
// 修改上述的代码const chunkName = `${chunkIndex}.${filemd5}.chunk`;const fd = new FormData();fd.append(chunkName, chunk);至此分片上传就大致完成了。
文件合并
文件合并,就是将上传的文件分片分别读取出来,然后整合成一个新的文件,比较耗IO,可以在一个新的线程中去整合。
for (let chunkId = 0; chunkId < chunks; chunkId++) { const file = `${uploadTmp}/${chunkId}.${checksum}.chunk`; const content = await fsPromises.readFile(file); logger.info(Messages.success(modules.UPLOAD, actions.GET, file)); try { await fsPromises.access(path, fs.constants.F_OK); await appendFile({ path, content, file, checksum, chunkId }); if (chunkId === chunks - 1) { res.json({ code: 200, message }); } } catch (err) { await createFile({ path, content, file, checksum, chunkId }); }}Promise.all(tasks).then(() => { // when status in uploading, can send /makefile request // if not, when status in canceled, send request will delete chunk which has uploaded. if (this.status === fileStatus.UPLOADING) { const data = { chunks: this.chunks.length, filename, checksum: this.checksum }; axios({ url: '/makefile', method: 'post', data, }) .then((res) => { if (res.data.code === 200) { this._setDoneProgress(this.checksum, fileStatus.DONE); toastr.success(`file ${filename} upload successfully!`); } }) .catch((err) => { console.error(err); toastr.error(`file ${filename} upload failed!`); }); }});- 首先使用access判断分片是否存在,如果不存在,则创建新文件并读取分片内容
- 如果chunk文件存在,则读取内容到文件中
- 每个chunk读取成功之后,删除chunk
这里有几点需要注意:
如果一个文件切割出来只有一个chunk,那么就需要在
createFile的时候进行返回,否则请求一直处于pending状态。await createFile({ path, content, file, checksum, chunkId });if (chunks.length === 1) { res.json({ code: 200, message });}makefile之前务必要判断文件是否是上传状态,不然在cancel的状态下,还会继续上传,导致chunk上传之后,chunk文件被删除,但是在数据库中却存在记录,这样合并出来的文件是有问题的。
文件秒传
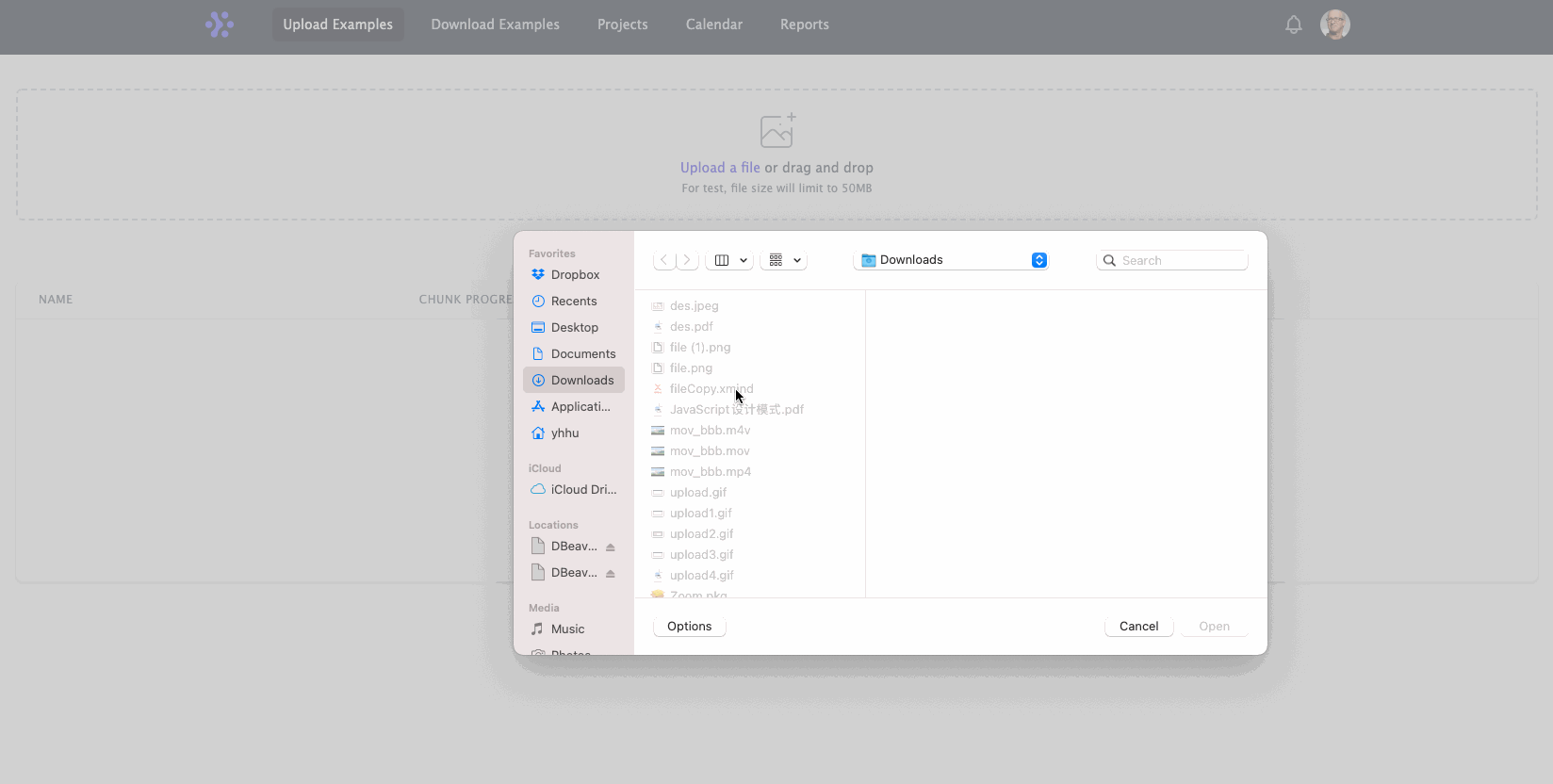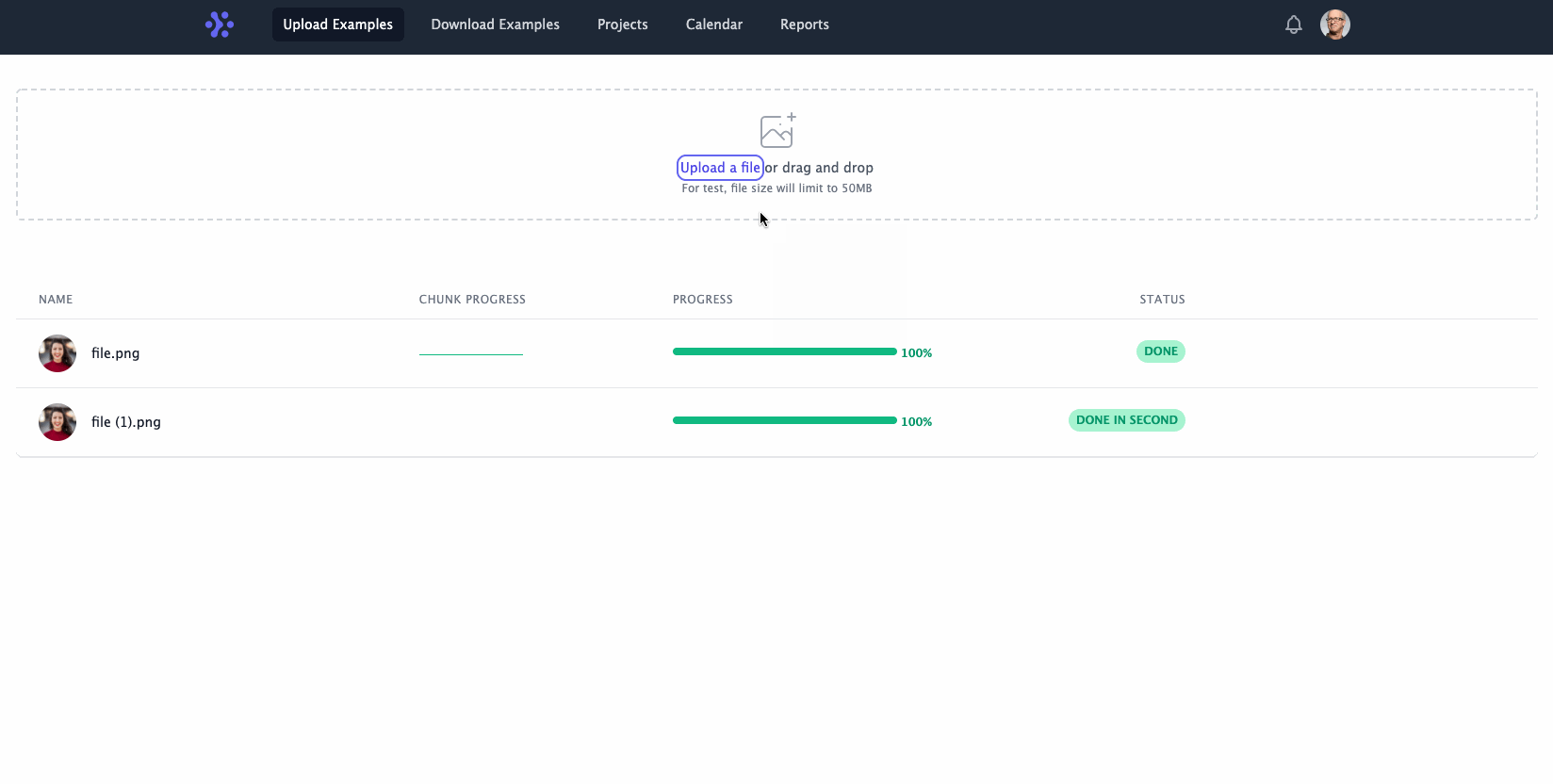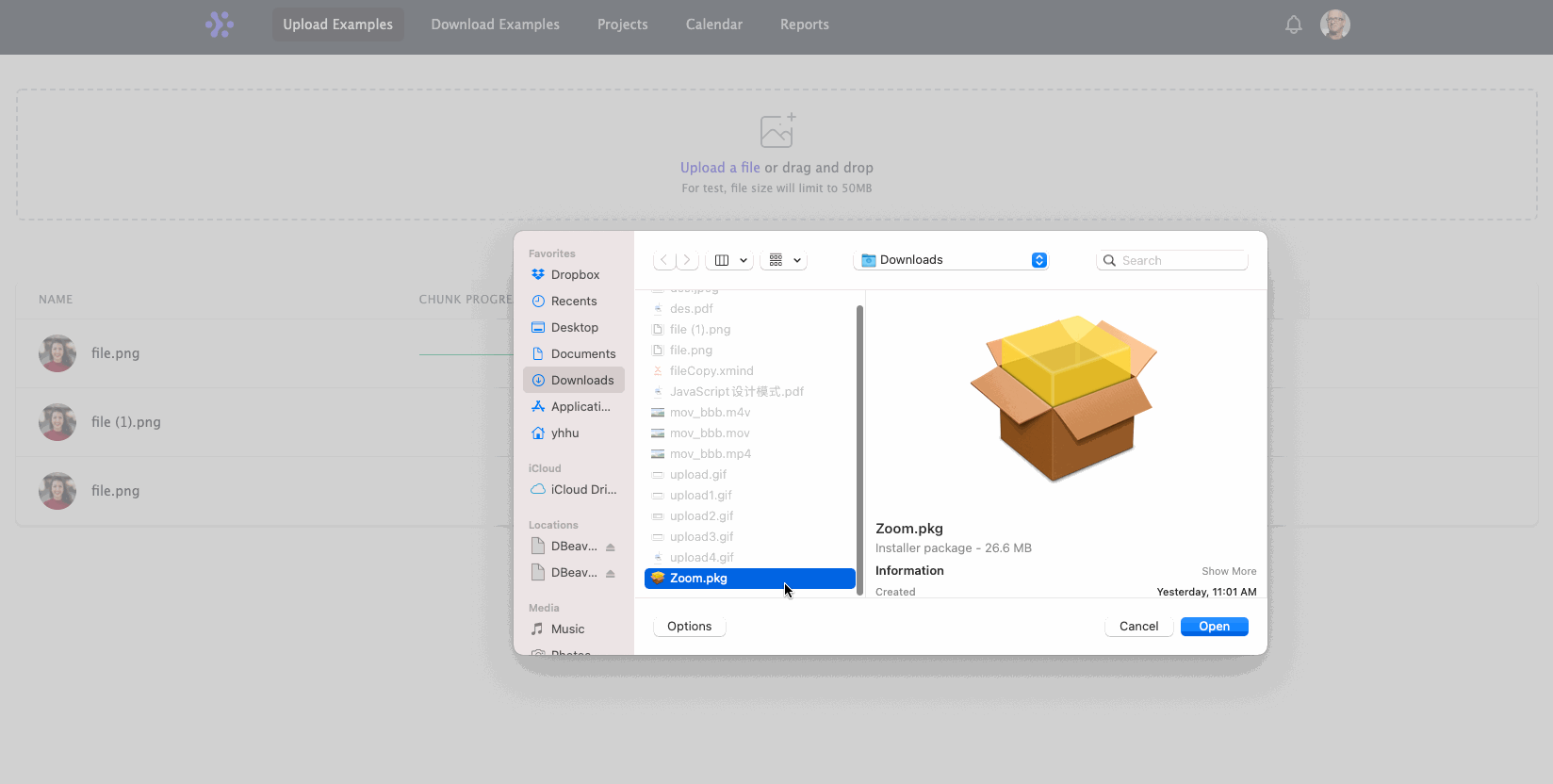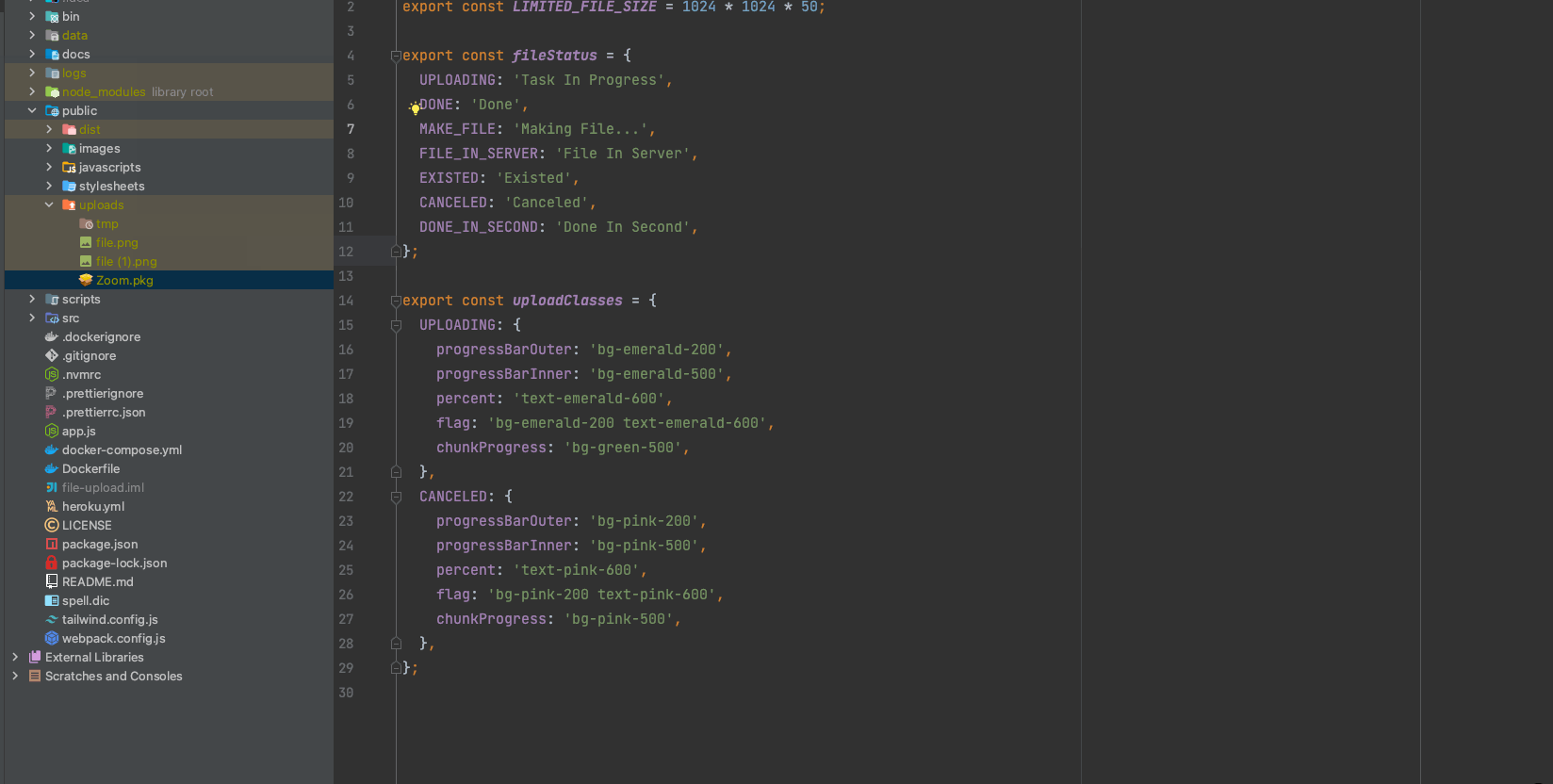
如何做到文件秒传,思考三秒,公布答案,3. 2. 1.....,其实只是个障眼法。
为啥说是个障眼法,因为根本就没有传,文件是从服务器来的。这就有几个问题需要弄清楚,
- 怎么确定文件是服务器中已经存在了的?
- 文件的上传的信息是保存在数据库中还是客户端?
- 文件名不相同,内容相同,应该怎么处理?
问题一:怎么判断文件已经存在了?
可以为每个文件上传生成对应的指纹,但是如果文件太大,客户端生成指纹的时间将大大增加,怎么解决这个问题?
还记得之前的slice,文件切片么?大文件不好做,同样的思路,切成小文件,然后计算md5值就好了。这里使用spark-md5这个库来生成文件hash。改造上面的slice方法。
export const checkSum = (file, piece = CHUNK_SIZE) => { return new Promise((resolve, reject) => { let totalSize = file.size; let start = 0; const blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice; const chunks = []; const spark = new SparkMD5.ArrayBuffer(); const fileReader = new FileReader(); const loadNext = () => { const end = start + piece >= totalSize ? totalSize : start + piece; const chunk = blobSlice.call(file, start, end); start = end; chunks.push(chunk); fileReader.readAsArrayBuffer(chunk); }; fileReader.onload = (event) => { spark.append(event.target.result); if (start < totalSize) { loadNext(); } else { const checksum = spark.end(); resolve({ chunks, checksum }); } }; fileReader.onerror = () => { console.warn('oops, something went wrong.'); reject(); }; loadNext(); });};问题二:文件的上传的信息是保存在数据库中还是客户端?
文件上传的信息最好是保存在服务端的数据库中(客户端可以使用IndexDB),这样做有几个优点,
- 数据库服务提供了成套的
CRUD,方便数据的操作 - 当用户刷新浏览器之后,或者更换浏览器之后,文件上传的信息不会丢失
这里主要强调的是第二点,因为第一条客户端也可以做😁😁😁
const saveFileRecordToDB = async (params) => { const { filename, checksum, chunks, isCopy, res } = params; await uploadRepository.create({ name: filename, checksum, chunks, isCopy }); const message = Messages.success(modules.UPLOAD, actions.UPLOAD, filename); logger.info(message); res.json({ code: 200, message });};问题三:文件名不相同,内容相同,应该怎么处理?
这里同样有两个解决办法:
- 文件copy,直接将文件复制一份,然后更新数据库记录,并且加上
isCopy的标识 - 文件引用,数据库保存记录,加上
isCopy和linkTo的标识
这两种方式有什么区别:
使用文件copy的方式,在删除文件的时候会更加自由点,因为原始文件和复制的文件都是独立存在的,删除不会相互干涉,缺点是会存在很多内容相同的文件;
但是使用引用方式复制的文件的删除就比较麻烦,如果删除的是复制的文件倒还好,删除的如果是原始文件,就必须先将源文件copy一份到任意的一个复制文件中,同时修改负责的记录中的isCopy为false, 然后才能删除原文件的数据库记录。
这里做了个图,顺便贴下:
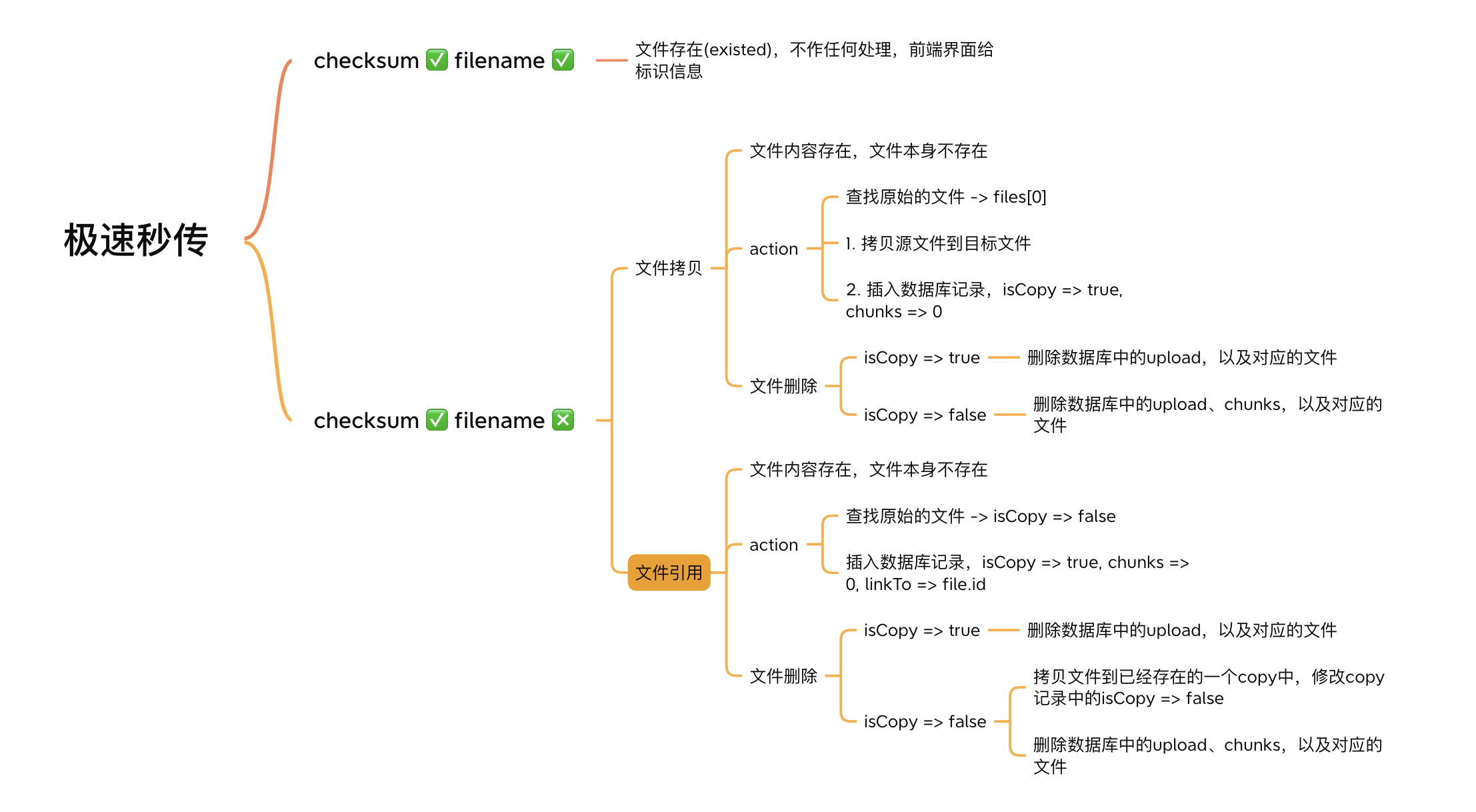
理论上讲,文件引用的方式可能更加好一点,这里偷了个懒,采用了文件复制的方式。
// 客户端uploadFileInSecond() { const id = ID(); const filename = this.file.name; this._renderProgressBar(id); const names = this.serverFiles.map((file) => file.name); if (names.indexOf(filename) === -1) { const sourceFilename = names[0]; const targetFilename = filename; this._setDoneProgress(id, fileStatus.DONE_IN_SECOND); axios({ url: '/copyfile', method: 'get', params: { targetFilename, sourceFilename, checksum: this.checksum }, }) .then((res) => { if (res.data.code === 200) { toastr.success(`file ${filename} upload successfully!`); } }) .catch((err) => { console.error(err); toastr.error(`file ${filename} upload failed!`); }); } else { this._setDoneProgress(id, fileStatus.EXISTED); toastr.success(`file ${filename} has existed`); }}// 服务器端copyFile: async (req, res) => { const sourceFilename = req.query.sourceFilename; const targetFilename = req.query.targetFilename; const checksum = req.query.checksum; const sourceFile = `${uploadPath}/${sourceFilename}`; const targetFile = `${uploadPath}/${targetFilename}`; try { await fsPromises.copyFile(sourceFile, targetFile); await saveFileRecordToDB({ filename: targetFilename, checksum, chunks: 0, isCopy: true, res }); } catch (err) { const message = Messages.fail(modules.UPLOAD, actions.UPLOAD, err.message); logger.info(message); res.json({ code: 500, message }); res.status(500); }}文件上传暂停与文件续传
文件上传暂停,其实是利用了xhr的abort方法,因为在案例中采用的是axios,axios基于ajax封装了自己的实现方式。
这里看看代码暂停代码:
const CancelToken = axios.CancelToken;axios({ url: '/upload', method: 'post', data: fd, cancelToken: new CancelToken((c) => { // An executor function receives a cancel function as a parameter canceler = c; this.cancelers.push(canceler); }),})axios在每个请求中使用了一个参数cancelToken,这个cancelToken是一个函数,可以利用这个函数来保存每个请求的cancel句柄。
然后在点击取消的时候,取消每个chunk的上传,如下:
// 这里使用了jquery来编写html,好吧,确实写🤮了$(`#cancel${id}`).on('click', (event) => { const $this = $(event.target); $this.addClass('hidden'); $this.next('.resume').removeClass('hidden'); this.status = fileStatus.CANCELED; if (this.cancelers.length > 0) { for (const canceler of this.cancelers) { canceler(); } }});在每个chunk上传的同时,我们也需要判断每个chunk是否存在?为什么?
因为发生意外的网络中断,上传到chunk信息就会被保存到数据库中,所以在做续传的时候,已经存在的chunk就可以不用再传了,节省了时间。
那么问题来了,是每个chunk单一检测,还是预先检测服务器中已经存在的chunks?
这个问题也可以思考三秒,毕竟debug了好久。
3.. 2.. 1......
看个人的代码策略,因为毕竟每个人写代码的方式不同。原则是,不能阻塞每次的循环,因为在循环中需要生成每个chunk的cancelToken,如果在循环中,每个chunk都要从服务器中拿一遍数据,会导致后续的chunk生成不了cancelToken,这样在点击了cancel的时候,后续的chunk还是能够继续上传。
// 客户端const chunksExisted = await this._isChunksExists();for (let chunkId = 0; chunkId < this.chunks.length; chunkId++) { const chunk = this.chunks[chunkId]; // 很早之前的代码是这样的 // 这里会阻塞cancelToken的生成 // const chunkExists = await isChunkExisted(this.checksum, chunkId); const chunkExists = chunksExisted[chunkId]; if (!chunkExists) { const task = this._chunkUploadTask({ chunk, chunkId }); tasks.push(task); } else { // if chunk is existed, need to set the with of chunk progress bar this._setUploadingChunkProgress(this.checksum, chunkId, 100); this.progresses[chunkId] = chunk.size; }}// 服务器端chunksExist: async (req, res) => { const checksum = req.query.checksum; try { const chunks = await chunkRepository.findAllBy({ checksum }); const exists = chunks.reduce((cur, chunk) => { cur[chunk.chunkId] = true; return cur; }, {}); const message = Messages.success(modules.UPLOAD, actions.CHECK, `chunk ${JSON.stringify(exists)} exists`); logger.info(message); res.json({ code: 200, message: message, data: exists }); } catch (err) { const errMessage = Messages.fail(modules.UPLOAD, actions.CHECK, err); logger.error(errMessage); res.json({ code: 500, message: errMessage }); res.status(500); }}文件续传就是重新上传文件,这点没有什么可以讲的,主要是要把上面的那个问题解决了。
$(`#resume${id}`).on('click', async (event) => { const $this = $(event.target); $this.addClass('hidden'); $this.prev('.cancel').removeClass('hidden'); this.status = fileStatus.UPLOADING; await this.uploadFile();});进度回传
进度回传是利用了,axios同样封装了相应的方法,这里需要显示两个进度
- 每个chunk的进度
- 所有chunk的总进度
每个chunk的进度会根据上传的loaded和total来进行计算,这里也没有什么好说的。
axios({ url: '/upload', method: 'post', data: fd, onUploadProgress: (progressEvent) => { const loaded = progressEvent.loaded; const chunkPercent = ((loaded / progressEvent.total) * 100).toFixed(0); this._setUploadingChunkProgress(this.checksum, chunkId, chunkPercent); },})总......
原文转载:http://www.shaoqun.com/a/833905.html
跨境电商:https://www.ikjzd.com/
airwallex:https://www.ikjzd.com/w/1011
zen-cart:https://www.ikjzd.com/w/1282
飞书互动:https://www.ikjzd.com/w/1319.html
某一天,在逛某金的时候突然看到这篇文章,前端大文件上传,之前也研究过类似的原理,但是一直没能亲手做一次,始终感觉有点虚,最近花了点时间,精(熬)心(夜)准(肝)备(爆)了个例子,来和大家分享。本文代码:github问题Knowingthetimeavailabletoprovidearesponsecanavoidproblemswithtimeouts.Currentimplementation
telegram:https://www.ikjzd.com/w/1734
营销神操作:美国人爱占星术,看亚马逊如何投其所好?:https://www.ikjzd.com/articles/21973
2019年亚马逊政策大盘点,亚马逊到底要干什么?:https://www.ikjzd.com/articles/21974
全方位揭秘!什么是亚马逊的Amazon global store?:https://www.ikjzd.com/articles/21977
图文详解:亚马逊账户信用卡信息更换实操:https://www.ikjzd.com/articles/21978
口述强壮的公么征服我 公让我欲仙欲死3b:http://lady.shaoqun.com/a/247070.html
口述:为保家产 我故意在公公面前滑落浴巾:http://www.30bags.com/m/a/249520.html
小玉面试体检被教授摸底全文阅读 应聘时医生慢慢探入:http://www.30bags.com/m/a/249675.html
吃过之后就不会觉得痛了。:http://lady.shaoqun.com/a/390517.html
事实上,大部分痛苦会自行消失:http://lady.shaoqun.com/a/390518.html
亚马逊遭打击!迫使出售整个FBA业务?:https://www.ikjzd.com/articles/146100
亚马逊对售后卡发声, 差评修改功能上线, Prime Day数据出炉让新卖家、新商品看到希望:https://www.ikjzd.com/articles/146099
No comments:
Post a Comment